第 1 章 内存与数据结构
1 内存与数据结构
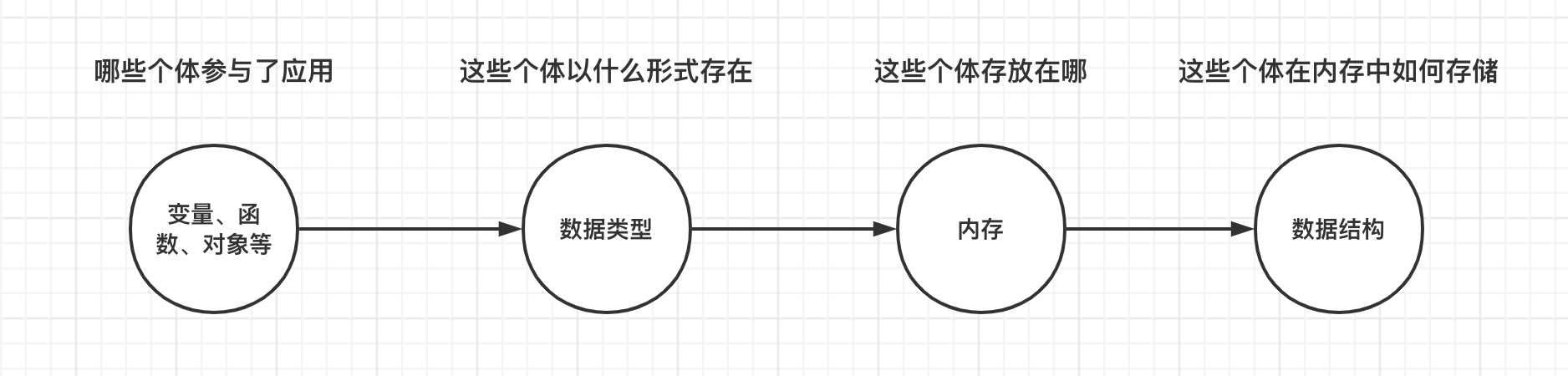
我们可以把一个页面,看成是一个完整的独立应用。
那么,哪些个体参与了应用的运行,这些个体以什么样的形式存在,这些个体要存放在哪里「内存中」,这些个体在内存中如何存放,都是我们要一一去了解的事情。
注意:本书籍的所有知识,都基于 ES6/ECMAScript2020 官方标准 进行讨论。
1.1 个体
讨论参与应用的个体,是讨论在应用运行过程中,哪些角色可能会参与应用运行的课题。
在 JavaScript 中,通常可以通过声明变量、函数、对象这三个方式,来明确它们。
// 声明一个变量
var a = 10;
// 声明一个函数
function add(a, b) {
return a + b;
}
// 声明一个对象
class M {}
上面的例子中,a, add, M 分别是不同个体的名字。我们可以通过这些名字,访问到具体个体的值。
1.2数据类型
讨论数据类型,是讨论个体以什么样的形式存在的课题。
ES6 中定义了 8 种数据类型。其中包括 7 种基础数据类型与一种引用数据类型「Object」。
基础数据类型 「primitive value」
基础数据类型,通常用来表达一些结构简单的数据。
| 基础类型 | 值 |
|---|---|
| Boolean | 只有两个值:true 与 false |
| Null | 只有一个值:null |
| Undefined | 只有一个值:undefined |
| Number | 所有数字 |
| String | 所有字符串 |
| Symbol | 符号类型 var sym = Symbol('tSymbol') |
| BigInt | 整数的末尾追加 n |
学习基础数据类型,最核心的关键点,是要理解到,基础数据类型的值,是不可改变的。
乍一听,好像有点不太对。我们在使用过程中,经常会遇到修改值的场景。例如数据的累加,字符串的变动等等。是不是和「不可改变」冲突了呢?
以数据累加为例,我们写一个小案例来验证一下。
let a = 1;
let b = a;
b++;
console.log(a); // 仍然为1
console.log(b); // 变成了2
分析一下上面的代码。我们声明一个变量 a, 并且声明一个变量 b,将 a 赋值给 b。这个时候,a 与 b 是等价的。然后我们试图去修改 b 的值,进行累加操作。最后发现一个奇怪的结果,a 的值没有变,可是 b 的值改变了。也就意味着,a b 的等价,并不表示他们是同一个值。我们用图例来表达这个过程。
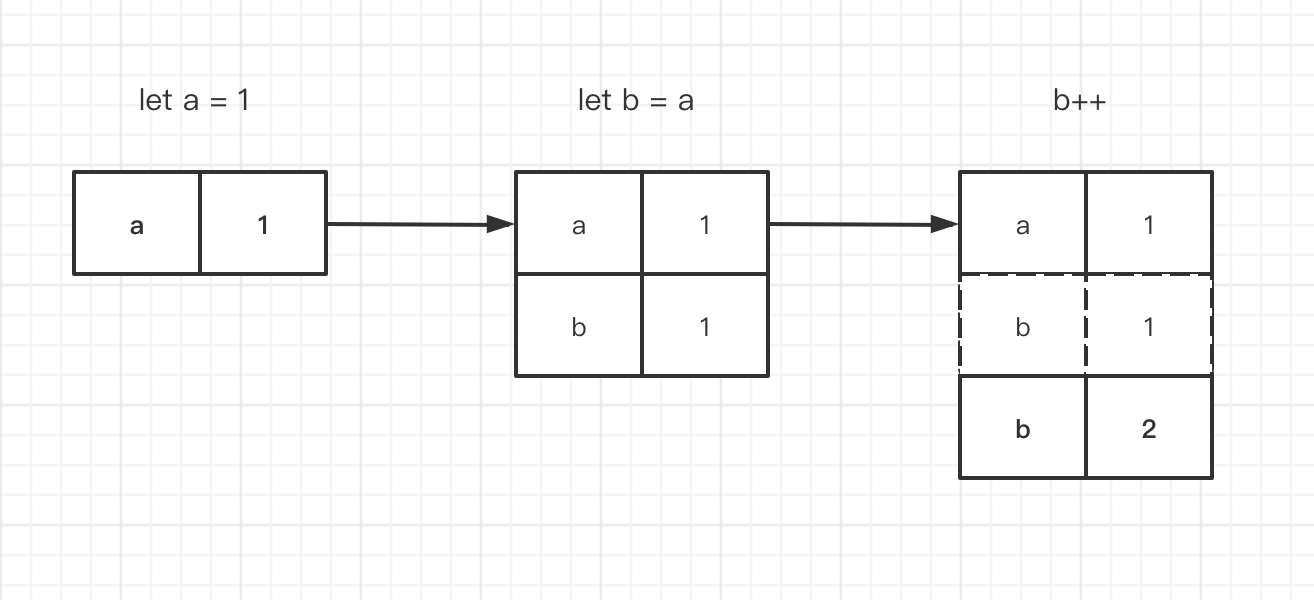
左侧表示变量,右侧表示具体的值。第三步 b 为1的结果被覆盖了,因此用虚线表示。
我们发现,变量名对应的值可能被改变,但是基础数据类型的值本身是没有改变的。对于变量 b 来说,是一个新的值跟他建立了对应关系。
因此,我们说,基础数据类型,是按值访问的。
当两个基础类型的变量进行比较时,本质上,也是他们的值在进行比较。
const a = 1;
const b = 1;
a == b // --> 1 == 1
下面字符串的案例也能说明问题
var str = 'hello world'
str[0] = 'K' // 试图修改字符串的第一个字符
console.log(str) // 打印结果:hello world
除了不可变性,基础数据类型还有一个需要我们关注的重点,那就是基础数据类型也能访问方法。
这就很奇怪,如果是一个对象,能够访问方法我们能够理解,基础数据类型也能访问方法其实细想一下就很奇怪。
var str = 'hello world'
str.charAt(0)
原因是因为当我们在访问字符串时,实际上依然是在访问一个对象。在 JavaScript 中,针对每一种基础数据类型,都有提供对应的包装对象,例如对于字符串而言,就有一个名为 String 的包装对象,当我们使用字符串变量访问方法时,实际上经历了如下三步代码
// 首先使用包装对象创建对象
var _str = new String('hello world')
// 然后使用包装对象的实例去访问方法
_str.charAt(0)
// 最后销毁该对象
_str = null
包装对象会在访问方法时临时生效,并在访问结束之后清除包装对象生成的实例。
引用数据类型「reference value」
当数据结构变得更加复杂,不再是单一的数字或者字符串,则需要引用数据类型来表达。例如我们想要表达一本书,需要知道书的名字,作者,发行日期等许多信息,才能完整的表达它。
const book = {
title: 'JavaScript 核心进阶',
author: '这波能反杀',
date: '2020.08.02'
}
与基础数据类型不同的是,引用数据类型的值是可以被改变的。
我们也写一个类似的案例来进行分析。
const book = {
title: 'JavaScript 核心进阶',
author: '这波能反杀',
date: '2020.08.02'
}
const b2 = book;
b2.author = '反杀';
console.log(book); // {title: "JavaScript 核心进阶", author: "反杀", date: "2020.08.02"}
console.log(b2); // {title: "JavaScript 核心进阶", author: "反杀", date: "2020.08.02"}
在这个案例中,我们声明了变量 book,它的值类型是一个引用数据类型。并且将 book 赋值给新的变量 b2。然后修改 b2 的 author 属性。结果我们发现,book 和 b2 的值,都发生了变化。我们用图例来表达这个过程。
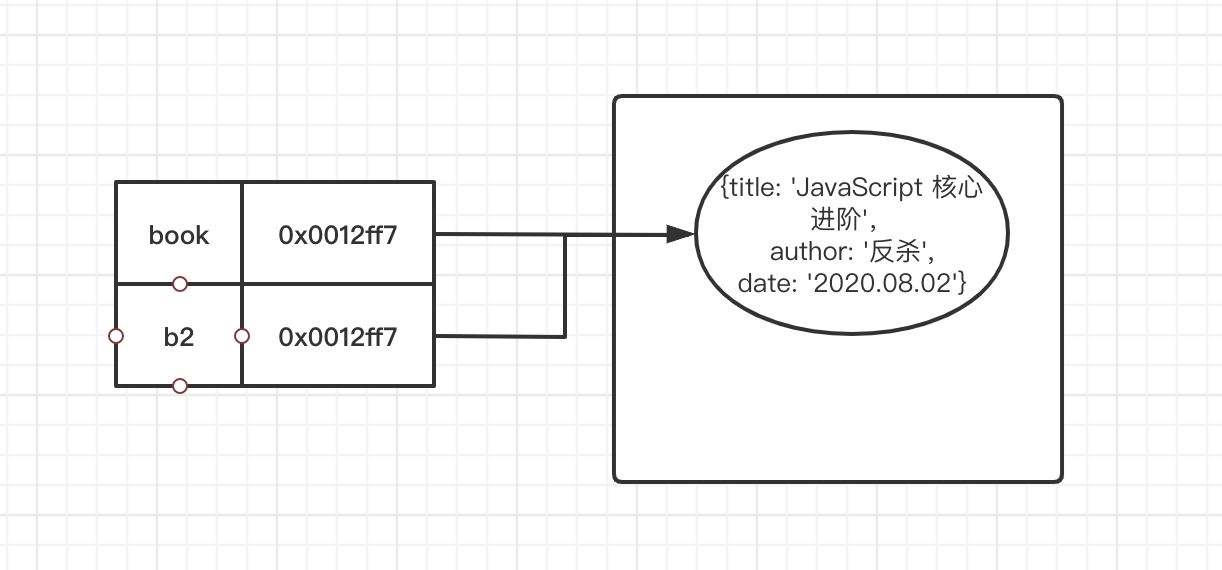
在上图中,与变量 book 建立直接映射关系的,并非引用类型本身,而是引用类型值本身在内存中的地址 0x0012ff7。因此,当我们执行 b2 = book 进行一个赋值操作时,并非如基础数据类型那样,值的本身有一份新的拷贝,而只是地址进行了一份拷贝。这种只拷贝地址的操作,我们也可以称之为浅拷贝。
那么自然的,当我们通过 b2 修改 author 字段时,book 对应的值自然也发生了改变,因为他们最终,都是指向同样的引用类型值。
因此我们说,引用数据类型,是按引用访问的。这里的引用,说的其实就是内存空间中的地址。
当两个引用数据类型在进行比较时,本质上,是他们的内存地址在进行比较。
const a = {}
const b = {}
a == b // false
上例中,由于 a 与 b 是两个分开创建的对象,尽管他们的值是一样的,但是他们在内存空间中的地址不一样,因此他们比较的结果也会不同。直接比较引用地址,我们称这样的操作为浅比较。
浅拷贝与浅比较,都是针对引用数据类型的概念,它们没有非常明确的界限来定义,在其他场景里,只比较一层数据结构,也被认为是浅比较,浅比较是低成本的比较方式,浅拷贝同理。
1.3 内存
内存是讨论参与应用的个体存放在哪里的课题。
大家都有过购买电脑的经验。在购买电脑时,我们常常会关注两个非常重要的指标:内存与硬盘。
这是计算机给应用程序提供的两种存储信息的途径。我们要研究变量、函数、对象等个体存放在哪里,就是要弄明白内存与硬盘存储的区别。
对于 CPU 而言,他们的区别非常明显。内存通常用于存储程序运行时的信息,CPU 可以通过寄存器直接寻址访问。因此,CPU 访问内存的速度是非常快的。
我们可以将大量的电影,图片等永久存储在硬盘中。与内存的区别就在于,CPU 并不能直接访问硬盘中的数据,它只能通过硬件控制器来访问。
| 对象 | 容量 | 访问速度 | CPU能否直接访问 | 存储时效 |
|---|---|---|---|---|
| 内存 | 小 | 快 | 能 | 程序运行时 |
| 硬盘 | 大 | 慢 | 不能 | 持久性 |
对于电脑而言,一个应用程序,我们下载下来,是安装在硬盘存储中,而当我们运行这个程序时,则是在内存中进行。
与之对应的,一个 JavaScript 应用程序,也是在内存中运行。我们也可以将一些数据做持久化存储,这就是我们常说的本地缓存。本质上来说,这些本地缓存也是存储在硬盘中。在浏览器中,提供了 localStorage 对象来帮助我们实现本地缓存。
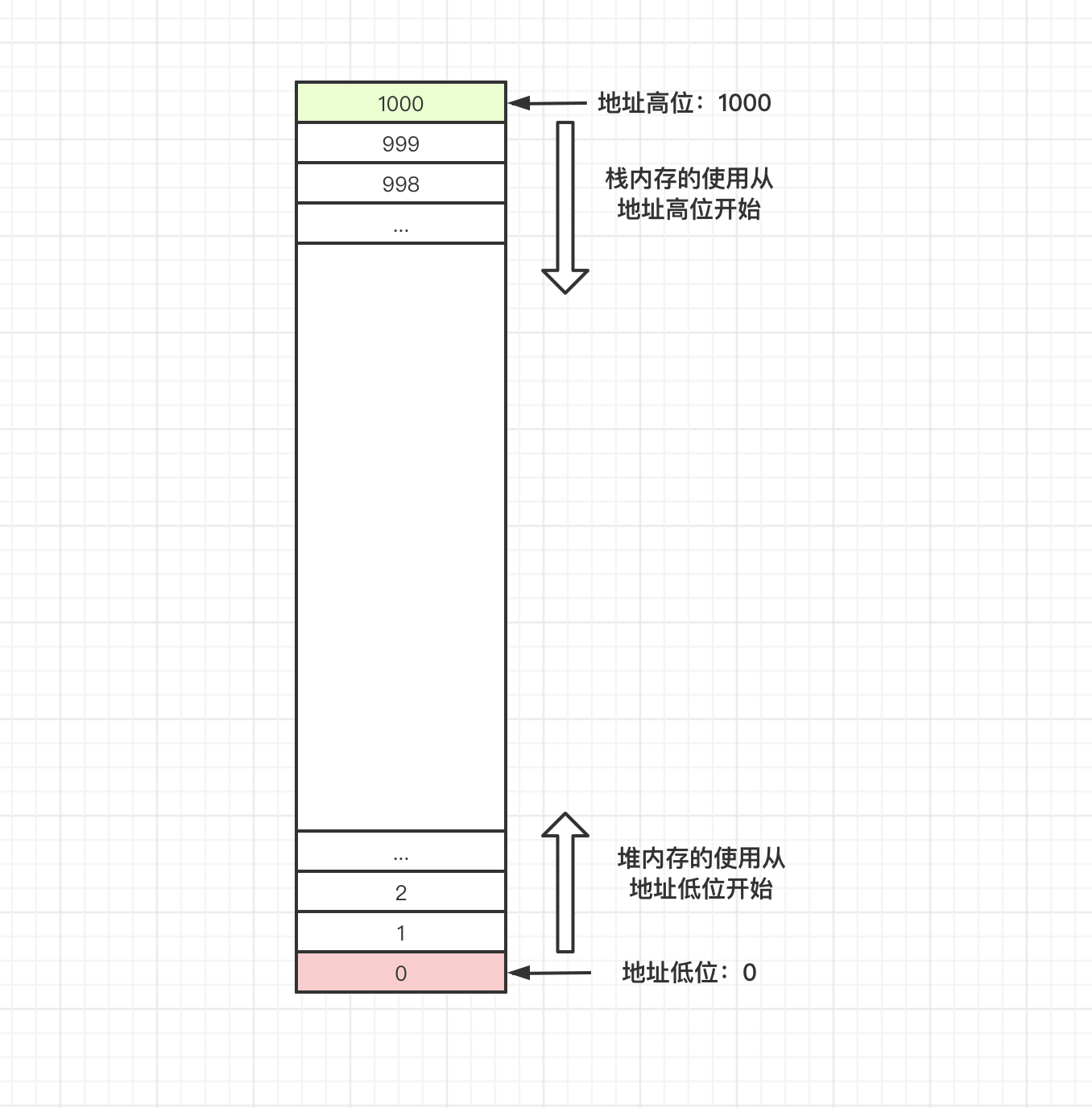
在 JavaScript 中,内存又分为栈内存与堆内存。栈内存与堆内存本身没有区别,只因为存取方式的差异,而有了不同。通常情况下,一个应用在运行时,操作系统会分配一份内存给它。假设这段内存地址为 0 ~ 1000。
内存地址本应该用 16 进制表示,但是为了便于理解,此处使用 10 进制表示
应用程序使用栈内存时,是从地址高位开始分配内存空间。使用堆内存时,是从地址低位开始分配空间。
1.4 基础数据结构
讨论数据结构,是讨论参与应用的个体,在内存中如何存放的课题。
其中,栈、堆、队列 是我们需要了解并掌握的三种基础数据结构。
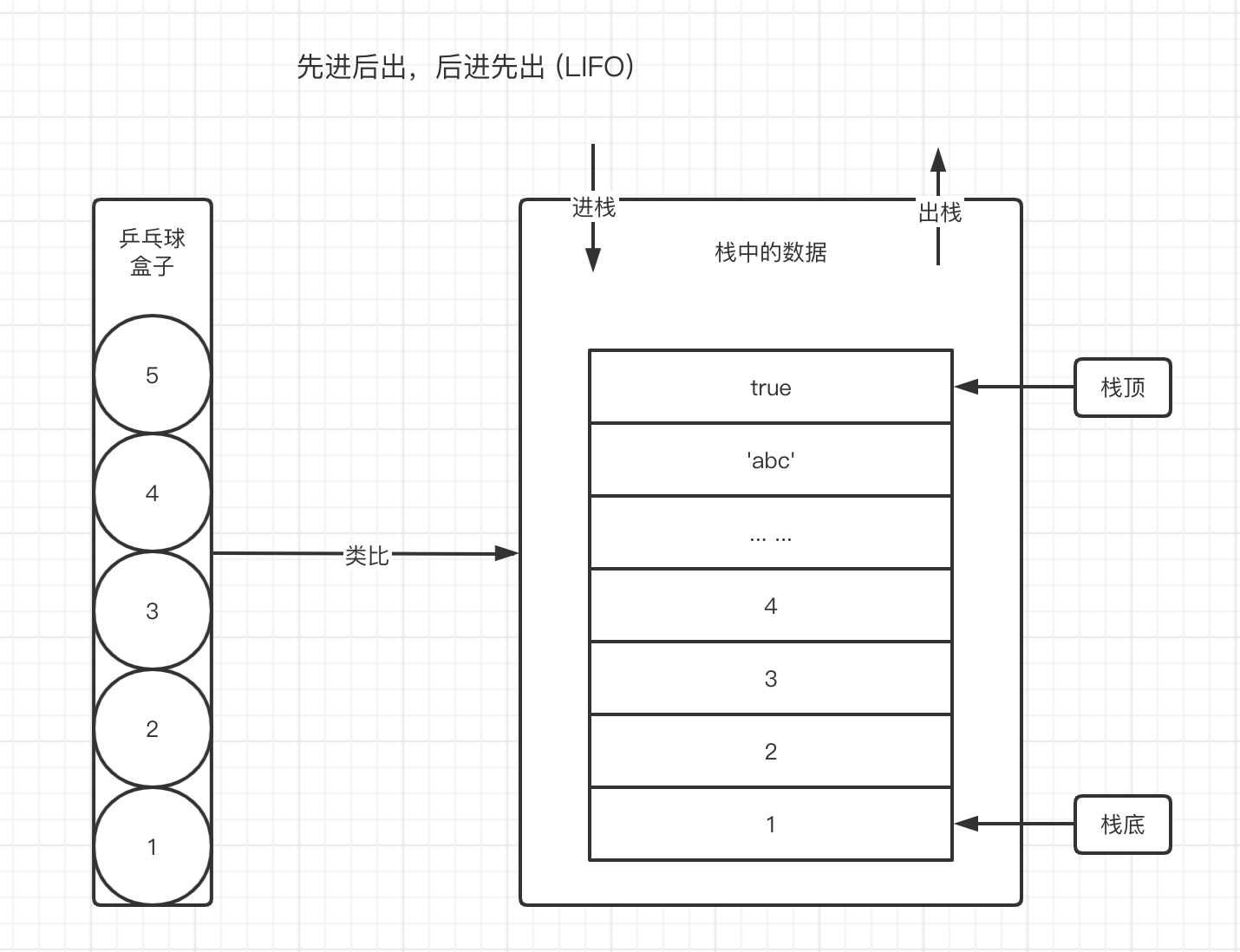
1.41 栈「stack」
在学习中遇到栈这个名词时,我们需要针对不同的场景去理解它所要表达的含义。
第一种场景,栈是一种数据结构。它表达的是对于数据的一种存取方式。这是一种理论基础。
要理解栈数据结构的存取方式,我们可以通过类比乒乓球盒子来分析。如下图所示。
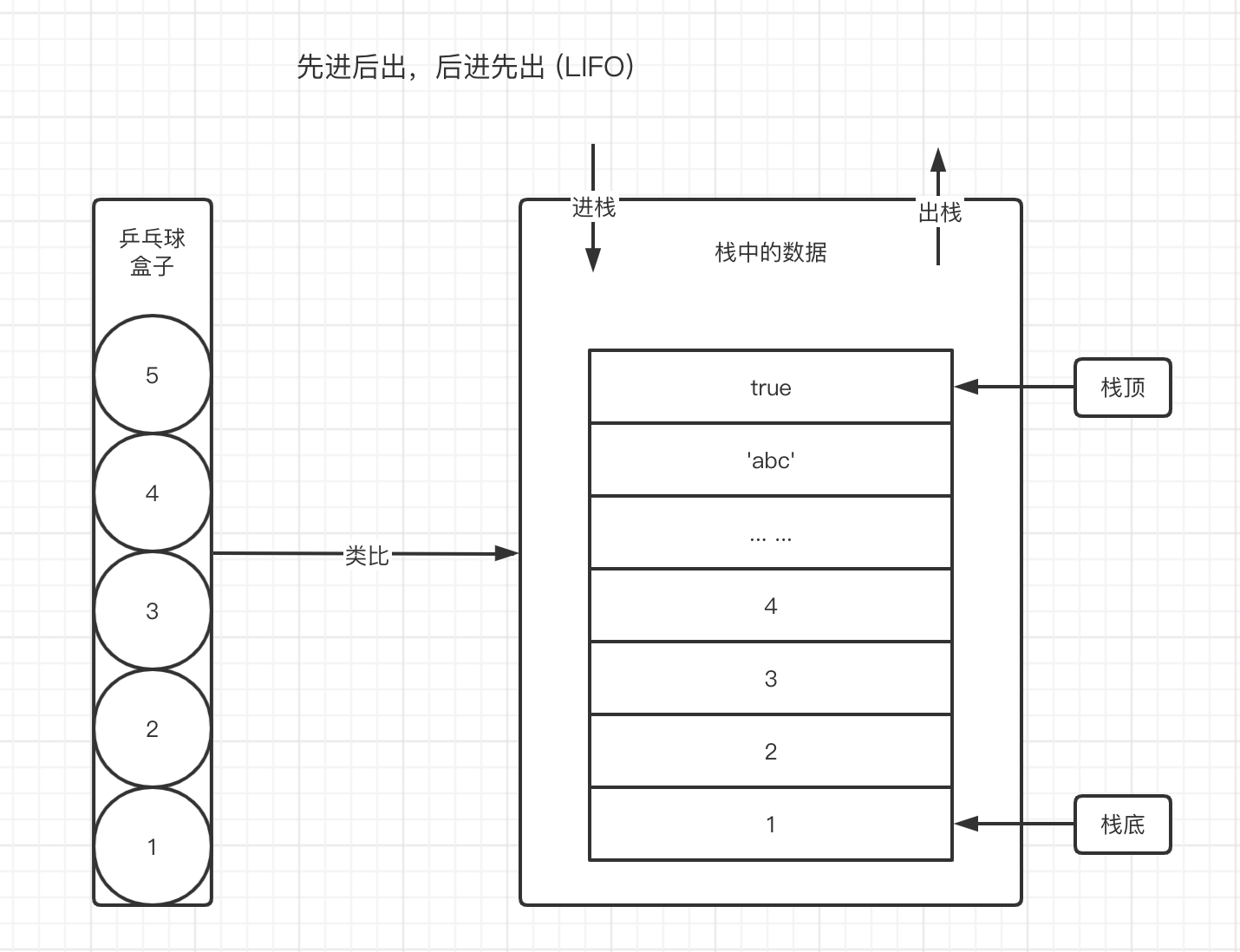
往乒乓球盒子中依次放入乒乓球,当我们想要取出来使用时,处于盒子中最顶层的乒乓球5,它一定是最后被放进去并且最先被取出来的。而我们想要使用最底层的乒乓球1,就必须要将上面的所有乒乓球取出来之后才能取出。但乒乓球1是最先放入盒子的。
乒乓球的存取方式与栈数据结构如出一辙。这种存取方式的特点我们总结为先进后出,后进先出(LIFO,Last In,First Out)。如上图右侧所示,处于栈顶的数据 true,最后进栈,最先出栈。处于栈底的数据 1,最先进栈,最后出栈。
在 JavaScript 中,数组「Array」提供了两个栈方法用来对应栈的这种存取方式。他们在实践中非常常用。
push:向数组末尾添加元素「进栈方法」 push 方法可以接受任意参数,把他们逐个添加到数组末尾,并返回修改后数组的长度
var a = [];
a.push(1); // a: [1]
a.push(2, 4, 6); // a: [1, 2, 4, 6]
var l = a.push(5); // a: [1, 2, 4, 6, 5] l: 5
pop:弹出数据最末尾的一个元素「出栈方法」 pop方法会将数据最末尾的一个元素删除,并返回被删除的元素。
var a = [1, 2, 3];
a.pop(); // a: [1, 2]
// a.pop()的返回结果为 3
数组提供的栈方法,可以很方便的让我们在实践中,模拟栈数据结构来解决问题。
第二种场景是将栈数据结构的理论运用于实践:栈内存空间。我们刚才已经知道,内存空间,因为操作方式不同才有了区别,而栈内存空间的操作方式,正是使用了栈数据结构的思维。
栈内存空间,是用于记录函数的执行记录,它代表了函数的执行顺序。因此也称之为函数调用栈「call Stack」。函数调用栈的相关知识,后续专门用一章来分析。
1.42堆「heap」
堆内存,与堆数据结构是完全不同的两回事。在学习时一定要仔细区分。
堆内存是内存中的空间区域。CPU 可以通过内存地址直接访问。
它的存取方式与在书架中取书的方式非常相似。书虽然整齐的放在书架上,但是我们只要知道书的名字,在书架中找到它之后就可以方便的取出,我们不用关心书的存放顺序,不用像从乒乓球盒子中取乒乓球那样,非得将上面的所有乒乓球拿出来之后才能取到中间的某一个乒乓球。
下面是一个大概的示意图。
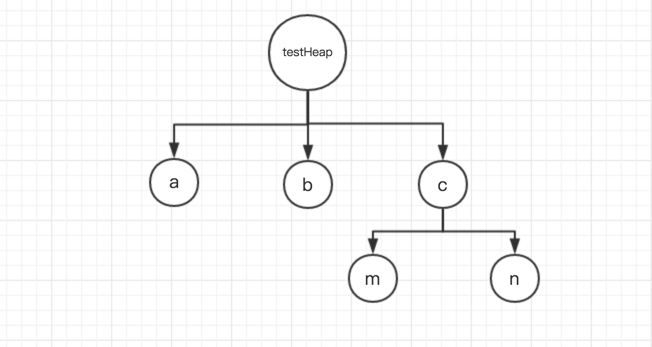
该示意图可以用字面量对象的形式体现出来。
var testHeap = {
a: 10,
b: 20,
c: {
m: 100,
n: 110
}
}
当我们想要访问a时,就只需要通过 testHeap.a来访问即可,我们不用关心a,b,c的具体顺序。
堆数据结构,是一种特殊的树状结构。他们关系大概如下:
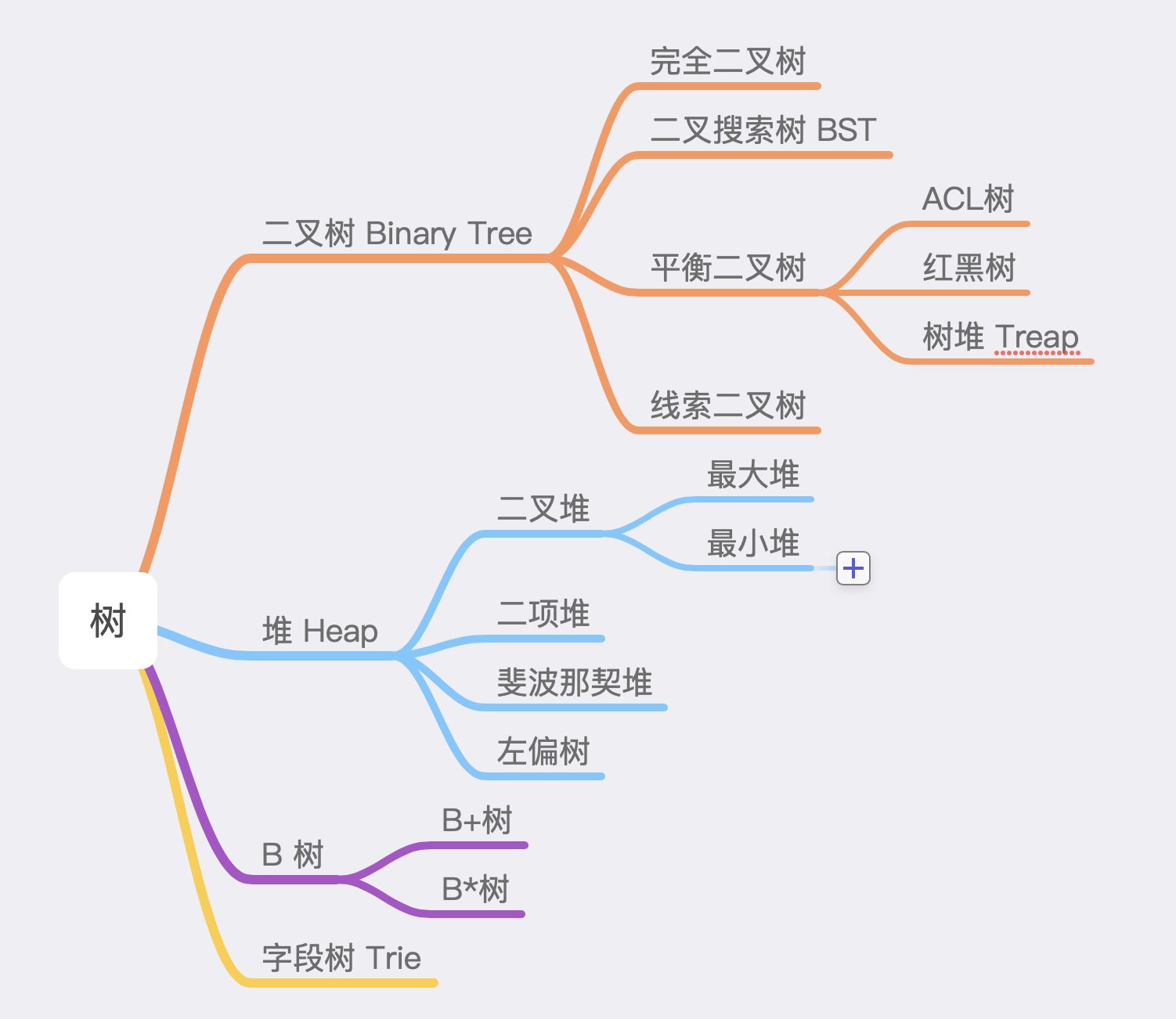
而为了易于存储与索引,在实践中,我们常常会使用二叉堆去解决问题。例如,在 v8 定时器实现原理中,我们会使用二叉堆「又称优先级队列」来决定哪个事件优先执行。
优先级队列是非常重要的知识,高级前端工程师必备
二叉堆是一颗完全二叉树。我们使用一个数组就完全可以存储完全二叉树。因此它非常易于存储。
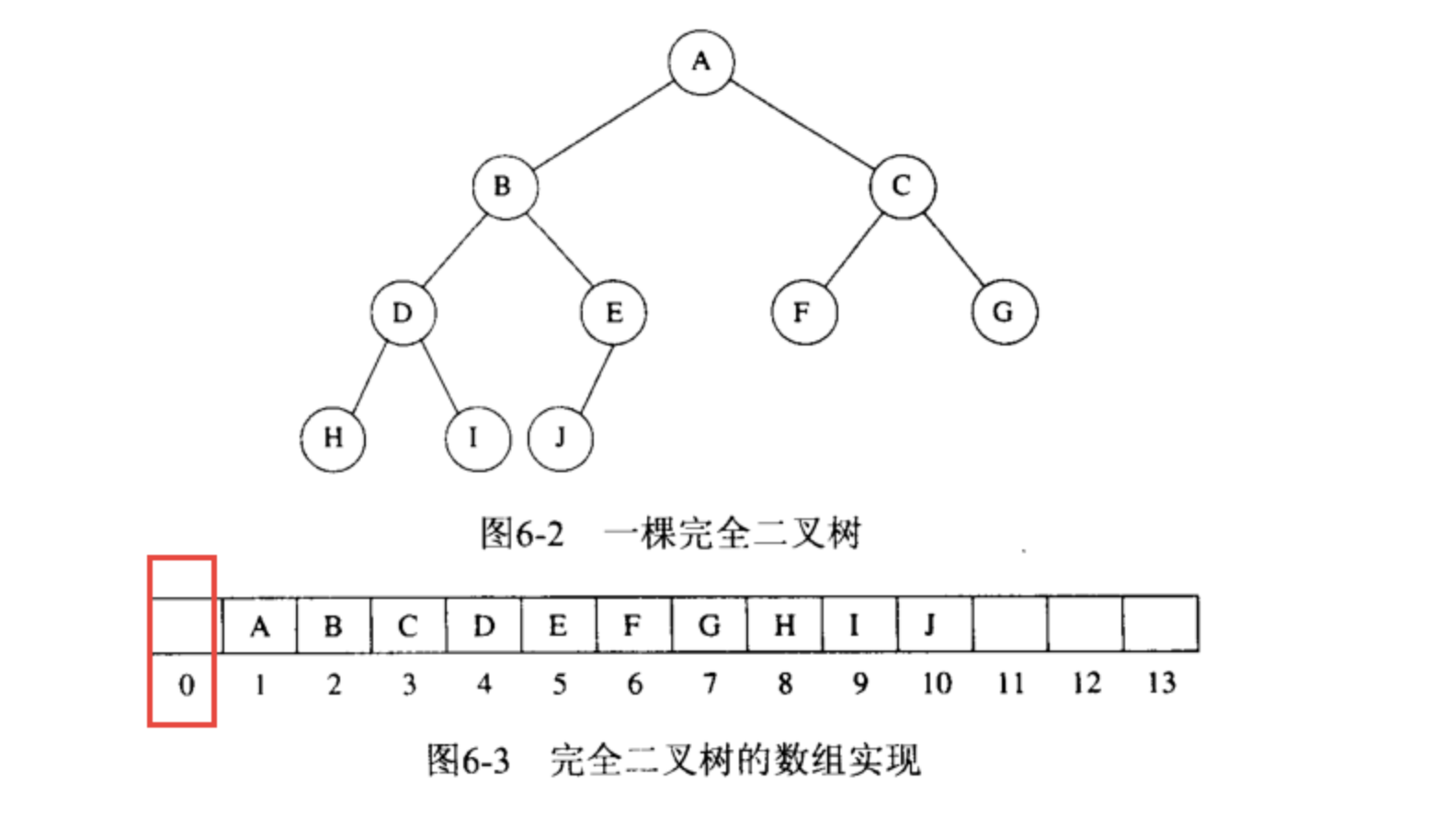
二叉堆又分最大堆和最小堆。
最大堆,又称大顶堆,父节点的键值总是大于等于任何一个子节点。 最小堆,又称小顶堆,父节点的键值总是小于等于任何一个子节点。
暂时就介绍到这里,具体的数据结构实现,我们在后续补充章节中详细说明。
1.43 队列「queue」
队列是一种先进先出(FIFO)的数据结构。正如排队过安检一样,排在队伍前面的人一定是最先过检的人。用以下的图示可以清楚的理解队列的原理。
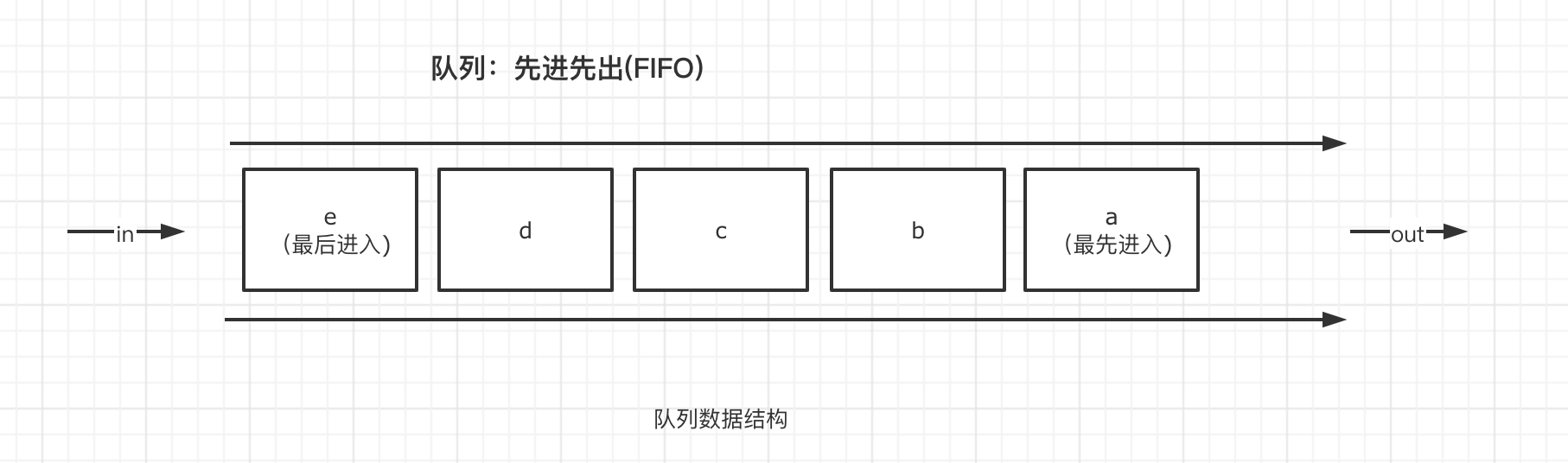
队列所要表达的核心思维是一种排队机制。因此运用到我们实践中就会有许多其他的规则,例如,位于队列首位的 人员 Peter 有其他的事情必须去完成,这个时候就需要在队列中暂时挂起,让其他的成员可以出队,当 Peter 事情做完之后,需要直接排在队列首位。
又例如在浏览器中,会将所有的异步事件都放于队列中等待执行,可需要满足一定条件才能直接执行。
因此此处队列的先进先出只是一个基础规则,结合运用到实践时,又会有新的限制条件出现。
1.5内存空间管理
当一个新的个体参与到应用的运行中来,我们首先需要给这个个体分配一份内存空间。而这个个体参与结束之后,它不再参与应用的运行了,我们就应该想办法让它把刚才所占的内存空间让出来,释放掉,这样才能有效的利用有限的内存空间。这个过程,就是内存管理。
对于栈内存而言,操作系统会自动回收出栈的内存空间。
对于堆内存而言,JavaScript 中提供了自动的垃圾回收机制,来释放内存。
var a = 20;
alert(a + 100);
a = null;
上面三条语句,可以对应内存管理的三个过程。
// 1. 给新的个体分配内存空间
var a = 20
// 2. 参与程序运行,使用内存
alert(a + 100)
// 3. 参与完毕,释放内存
a = null
垃圾回收主要依靠「引用」的概念。当一块内存空间中的数据能够被访问时,垃圾回收器就认为「该数据能够被获得」,也就意味着,这份数据可能还需要使用。不能够被获得的数据,就会被打上标记,并释放对应的内存空间。这种方式叫做标记-清除算法。
这个算法会设置一个全局对象,并定期的从全局对象开始查找,垃圾回收器将会找到所有可以获得与不能够被获得的数据。
因此在上面的简单例子中,当我们将 a 的值设置为 null,那么刚开始分配的 20,就无法被访问到了,很快就会被自动回收。
注意:在全局中,垃圾回收器无法判断全局声明的内存什么时候应该释放,因此我们在开发中,需要尽量避免使用全局变量。如果使用了全局变量,最好建议不再使用时,通过a = null 这样的方式释放引用,以确保能够及时回收。
1.6小结
本文以一个独立的完整应用作为思维的出发点,去思考当应用运行时,哪些个体参与,这些个体以什么形式存在,这些个体要放在哪里,怎么放等问题,从而轻松将数据类型,内存,数据结构等知识串联。这些看上去零散的知识,都是为了解决应用需要运行这个实际的问题,而提出的解决方案。
1.7思考题:
下面代码执行后,变量 m 的值是否被改变了,为什么?
const m = {
a: 1,
b: 2
}
function foo(arg) {
arg.a = 20;
}
foo(m)
2 数据结构:栈
栈数据结构的基础理论:先进后出,后进先出。
我们需要用代码体现出来,才算是真正的掌握了栈的思维。
在上一章介绍了数组的栈方法,我们可以依赖于数组,快速实现栈对象。
class Stack {
constructor() {
// 特别关注,此处的基础数据为数组
this.items = []
}
push(node) {
this.items.push(node)
}
pop() {
this.items.pop()
}
peek() {
return this.items[this.items.length - 1]
}
isEmpty() {
return this.items.length === 0
}
clear() {
this.items = []
}
}
这种基于数组的实现方式非常简单,因为数组本身就已经实现了一部分栈的特性,因此,我们几乎不用处理额外的逻辑,只是在数组之外套了一层无意义的代码就能实现。
那如果我们不依赖已经具备栈特性的数组,自己来实现应该怎么做呢?
熟悉原型链之后我们会知道,原型链的终点是 Object 原型对象。因此,在 JavaScript 中,最基础的数据结构表达,就是一个 Object 对象。例如对于数组来说,Array 对象中的基础数据结构,应该是这样子
{
0: 'Tom',
1: 'Tony',
2: 'Jim'
}

实现栈数据结构,也应该跟数组一样,以对象字面量的表达方式,来作为数据结构的基础。实现如下:
class Stack {
constructor() {
this.items = {}
this.length = 0
}
push(node) {
this.items[this.length] = node;
this.length++
}
pop() {
if (this.isEmpty()) {
return null;
}
this.length--
const r = this.items[this.length]
delete this.items[this.length]
return r
}
// 获取栈顶节点
peek() {
if (this.isEmpty()) {
return null
}
return this.items[this.length - 1]
}
isEmpty() {
return this.length === 0
}
clear() {
this.items = {}
this.length = 0
}
}
上例以最基础的对象作为基础数据结构存储栈内容,声明实例并且往栈中添加几个元素,大概长这样。

const stack = new Stack()
stack.push({a: 1})
stack.push({b: 2})
stack.push({c: 3})
还需要继续优化。
在我们的设想中,Stack 对象中的基础数据 items 应该只能通过 push, pop, clear 等 api 来修改。但是我们发现,如果 Stack 的实现仅仅如此,我们就还可以通过直接访问 items 的方式来修改它。这违背了我们的初衷,也违背了栈的基础思想。
// 可以这样直接修改
stack.items = {}
因此,在这里,items 只能作为私有变量被保护起来,才能避免出现这样的情况。在 class 语法中,我们可以直接使用 # 的方式,直接指定对应的变量为私有变量。
class Demo {
// 属性名前面加上 #,即为私有变量
#length = 0
constructor() {
this.#items = {}
}
}
不过遗憾的是,私有变量语法,各浏览器的支持程度并不高。因此我们可以使用基础数据类型 Symbol 来模拟私有变量,避免外部的直接访问。
代码如下:
class Stack {
constructor() {
this._i = Symbol('Stack')
this[this._i] = {}
this.length = 0
}
push(node) {
this[this._i][this.length] = node;
this.length++
}
pop() {
if (this.isEmpty()) {
return null;
}
this.length--
const r = this[this._i][this.length]
delete this[this._i][this.length]
return r
}
getItems() {
return this[this._i]
}
// 获取栈顶节点
peek() {
if (this.isEmpty()) {
return null
}
return this[this._i][this.length - 1]
}
isEmpty() {
return this.length === 0
}
clear() {
this[this._i] = {}
this.length = 0
}
}
当然,Symbol 也并非完全不能访问,我们可以通过
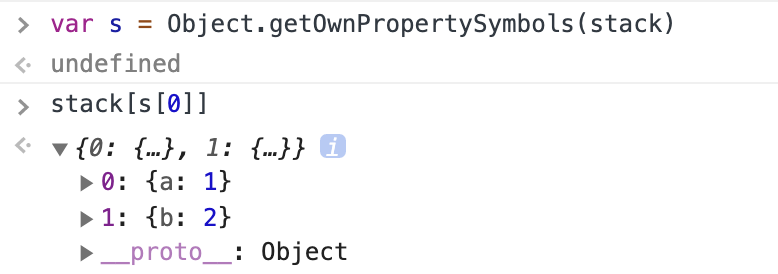
Object.getOwnPropertySymbols(stack)
来访问实例 stack 的 Symbol 属性。
2.1 实战:
利用上面的栈对象,封装一个十进制转二进制的方法
我们知道,二进制是一堆由 0 和 1 组合而成的数字。它的特点就是 「逢 2 进 1」。那么如果需要要将 10 进制 的数字,转化为二进制的数字,应该怎么做呢?
在我上大学时的教科书上提供了一种方法,叫做「相除取余数」。
什么意思呢?举一个例子,我们要将数字 11 转化为二进制。那么就依次有
11 / 2 = 5 余 1 // 使用计算结果的整数 5,继续下一次计算
5 / 2 = 2 余 1
2 / 2 = 1 余 0
1 / 2 = 0 余 1
这里,我们得到了每一次计算的余数,把所有的余数拼接起来,就是最终的二进制结果,为 1011 。再换一个数字 20,用这个逻辑继续推演一下
20 / 2 = 10 余 0
10 / 2 = 5 余 0
5 / 2 = 2 余 1
2 / 2 = 1 余 0
1 / 2 = 0 余 1
那么 20 转化为二进制的结果,就是 10100
我们使用代码来实现这个推演过程,只需要在每一次计算时,将余数保存压入栈中,最后将所有栈中的数字拼接起来即可得到二进制结果。
function decimalToBinary(number) {
// 声明一个栈容器
const stack = new Stack()
let result = ''
while(number > 0) {
// 将每一次计算的余数放入栈容器中
stack.push(number % 2)
// 计算下一次参与运算的结果
number = Math.floor(number / 2)
}
// 拼接栈中的所有余数,得到二进制结果
while(!stack.isEmpty()) {
result += stack.pop()
}
return result
}
console.log(decimalToBinary(11)) // 1011
console.log(decimalToBinary(20)) // 10100
console.log(decimalToBinary(25)) // 11001
使用同样的方式,我们可以封装一个通用方法,用于将 10 进制转化为 2/8/16 进制的数字。具体代码如下:
/***
* @desc 通用,10进制转其他进制
* @param {number} number 10进制数字
* @param {number} bs 2进制,8进制,16进制
* @return {string} 转换结果
**/
function converter(number, bs) {
const stack = new Stack()
const digits = '0123456789ABCDEF'
let result = ''
while(number > 0) {
stack.push(number % bs)
number = Math.floor(number / bs)
}
while (!stack.isEmpty()) {
result += digits[stack.pop()]
}
return result
}
console.log(converter(11, 2)) // 1011
console.log(converter(20, 2)) // 10100
console.log(converter(25, 2)) // 11001
console.log(converter(25, 8)) // 31
console.log(converter(1231, 16)) // 4CF
2.2 实战:
有效的括号
在 LeetCode 中,有这样一道简单算法题。
给定一个只包括 小括号 '(' ')' ,中括号 '[' ']' 大括号 '{' '}' 的字符串,判断字符串是否有效。
有效字符串需要满足:
- 左括号必须用相同类型的右括号闭合
- 左括号必须以正确的顺序闭合
示例:
input:'{}'
out: true
input: '()[]{}'
out: true
input: '(]'
out: false
input: '([)]'
out: false
input: '{[]}'
out: true
也就是说,每一个括号,都必须被正确闭合。这个很好理解,而我们要写一个方法来判断字符串的括号是否都正确闭合了,应该怎么办呢?
分析一下,如果我们借助栈的思维来解决问题,我们遍历目标字符串,第一个字符串放入栈中,如果接下来的一个字符串,刚好能够匹配,我们可以将栈中的字符串删除,不能匹配,则继续压入栈中。这样,当字符串的每一个字符都遍历完成之后,如果所有的字符串都成功正确匹配,那是不是栈中应该是空的呀?所以借助这个思路,我们来实现该方法
function isValid(s) {
const stack = new Stack()
for (var i = 0; i < s.length; i++) {
// 当前字符
const c = s[i]
// 栈顶字符
const p = stack.peek()
if (c == ')' && p == '(' || c == ']' && p == '[' || c == '}' && p == '{') {
// 匹配上了,p 出栈,否则,c 入栈
stack.pop()
} else {
stack.push(c)
}
}
// 最后,如果栈为空,则表示完全匹配,否则表示没有完全正确匹配
return stack.isEmpty()
}
console.log(isValid('()')) // true
console.log(isValid('()[]{}')) // true
console.log(isValid('(]')) // false
console.log(isValid('([)]')) // false
console.log(isValid('{[]}')) // true
2.3 思考题:
你在实践场景中,哪些地方运用了栈的基础思维来解决问题?
3 数据结构:堆
堆数据结构,是树中的一种。在实践中,我们更常用的堆数据结构就是二叉堆。
二叉堆能够实现优先级队列「Priority Queue」。
Linux 内核中对各个进程的调度分配,定时器的实现原理,React Fiber 的任务调度分配,都利用了优先级队列的思维来解决问题。因此作为一名合格的高级前端工程师,优先级队列是必须要掌握的重要知识点。
二叉堆中,每一个节点都必须是可比较的,否则就无法判断优先级
二叉堆是一颗完全二叉树:即在树结构中,除了最后一层,其他节点都是完整的「每一个节点都拥有左右两个子节点」。它分为两种类型:
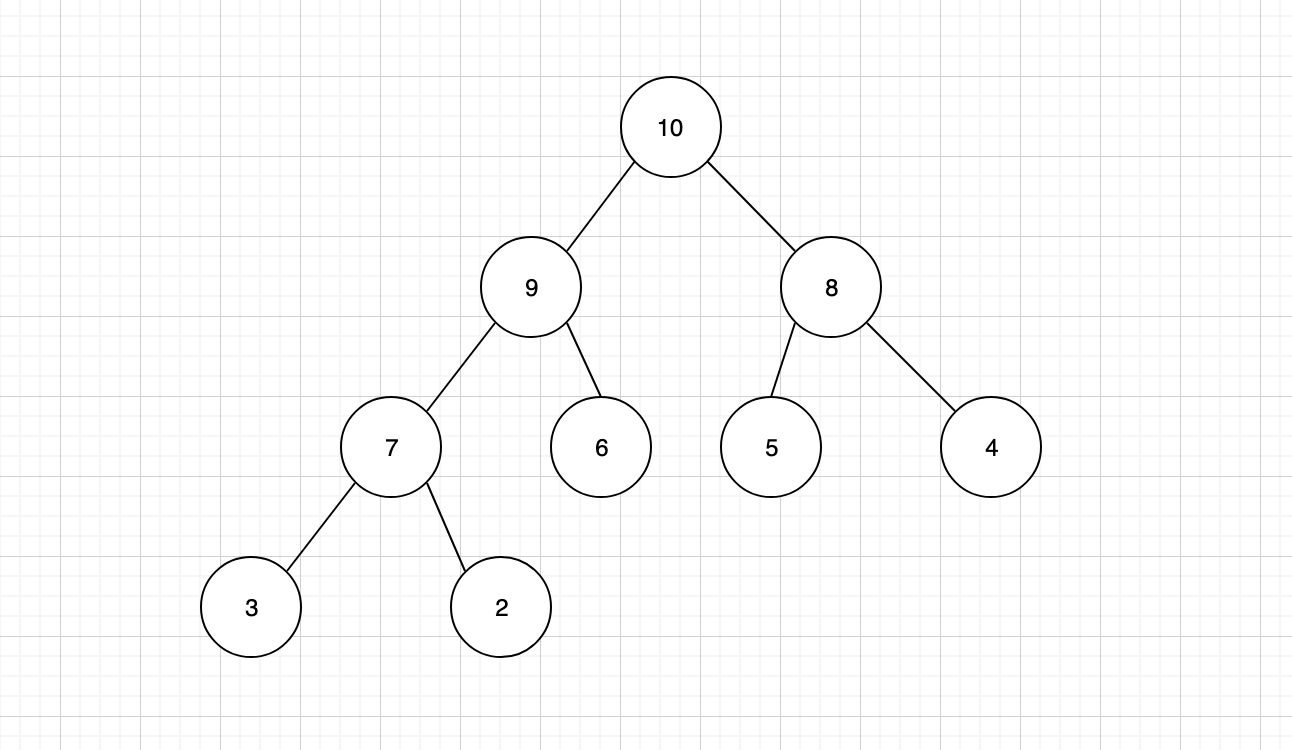
- 最大堆,又称为大顶堆,任何父节点的键值,都大于等于任何一个子节点。最大堆的根节点为堆顶,堆顶元素是整个堆中的最大值。
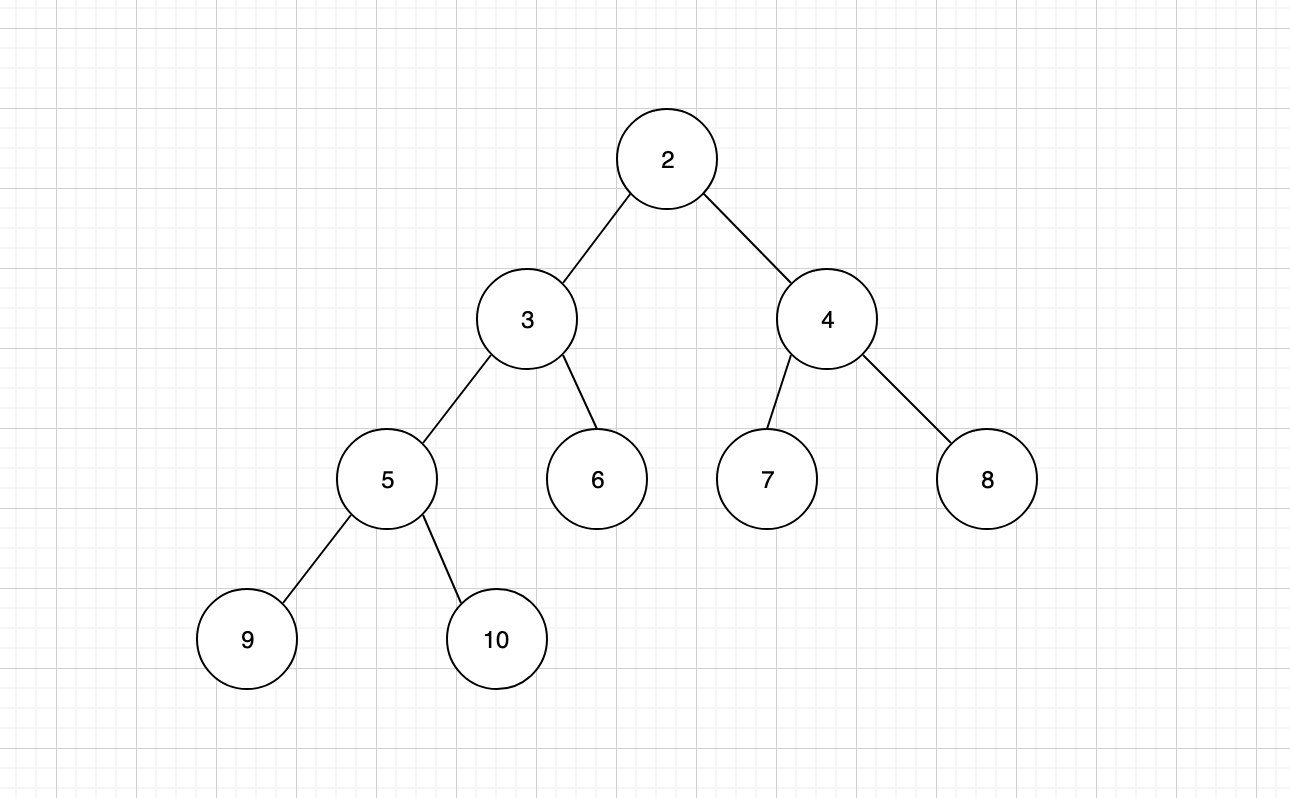
- 最小堆,又称为小顶堆,任何父节点的键值,都小于等于任何一个子节点。最小堆的根节点为堆顶,堆顶元素是整个堆中的最小值。
对于二叉堆,只有几个常规操作:插入节点,删除节点,以及构建二叉堆。
3.1 插入节点
二叉堆的节点插入,只能是二叉堆树结构中的最后一个位置。以上面的最小堆为例,我想要插入一个值为 1 的节点。
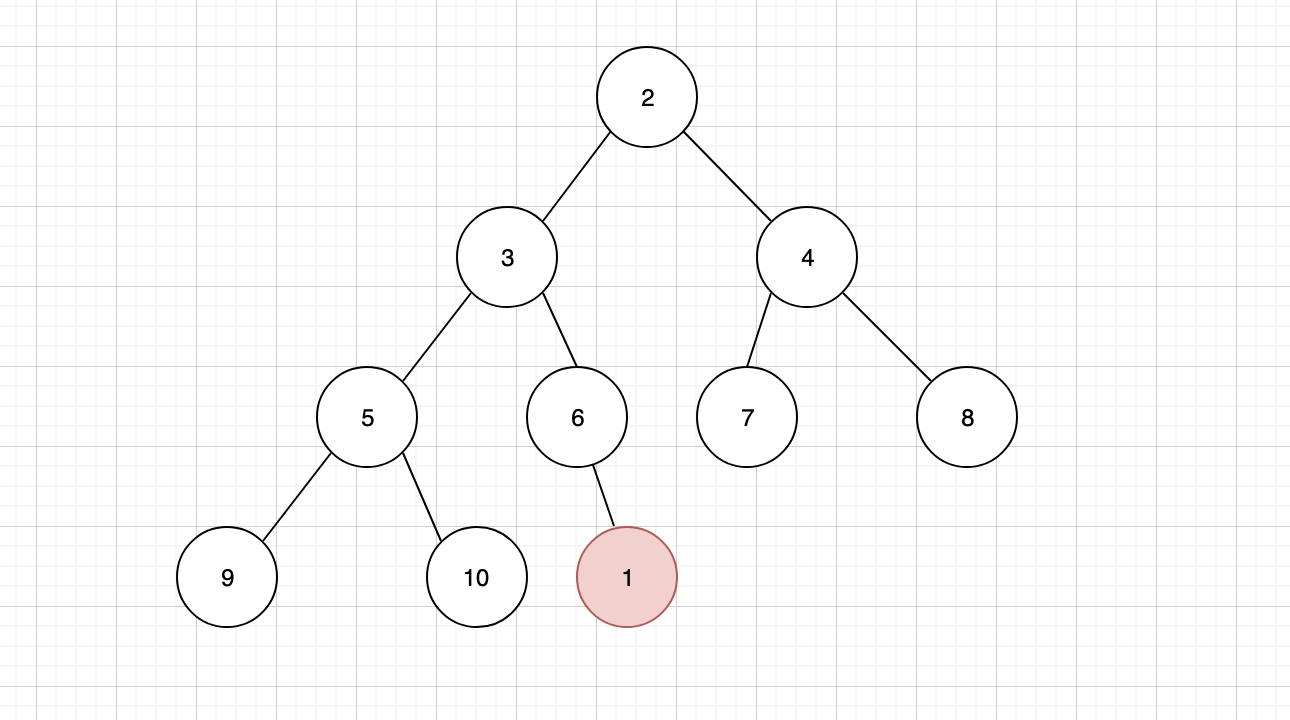
插入之后,我们发现并不符合小顶堆的规则,这个时候就需要进行「上浮」调整。将插入的子节点,与其父节点进行比较,如果子节点小于父节点,那么按照小顶堆的规则,就必须将父子节点进行互换
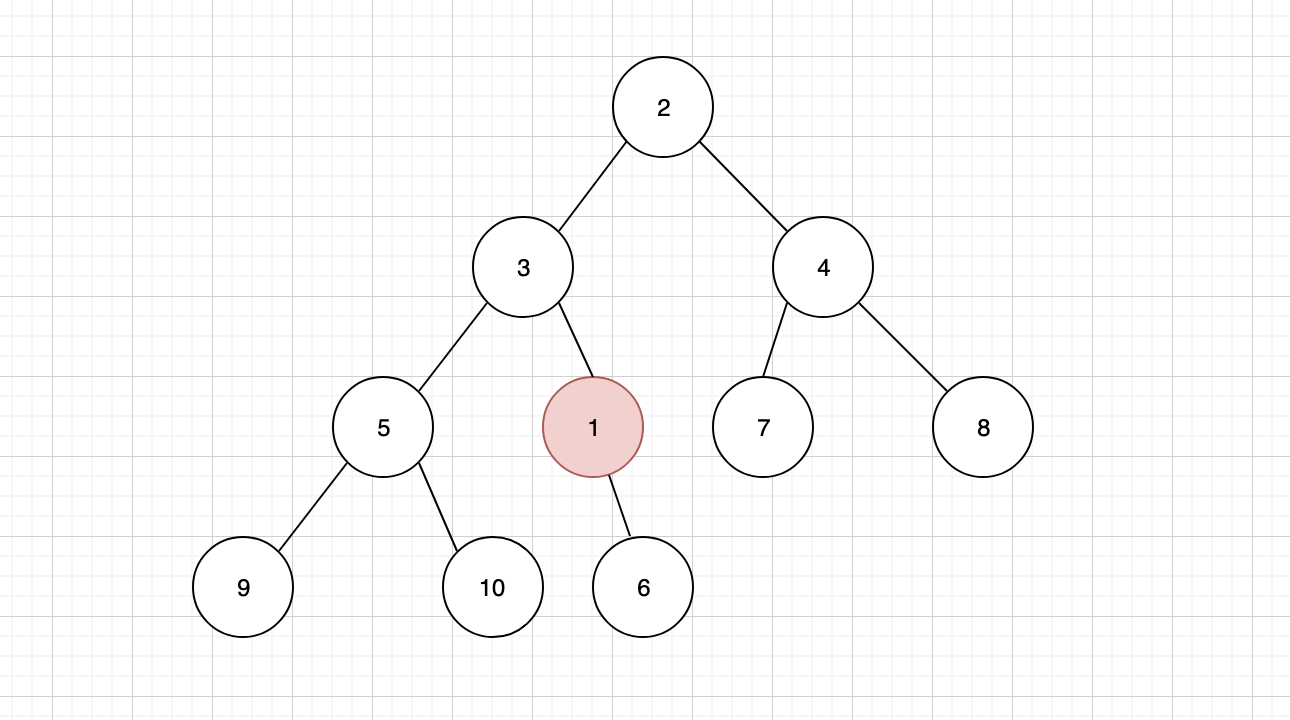
节点 1 上浮之后,还需要继续跟其新的父节点进行比较,我们发现它的父节点 3 还是要比 1 大,那么还要继续上浮
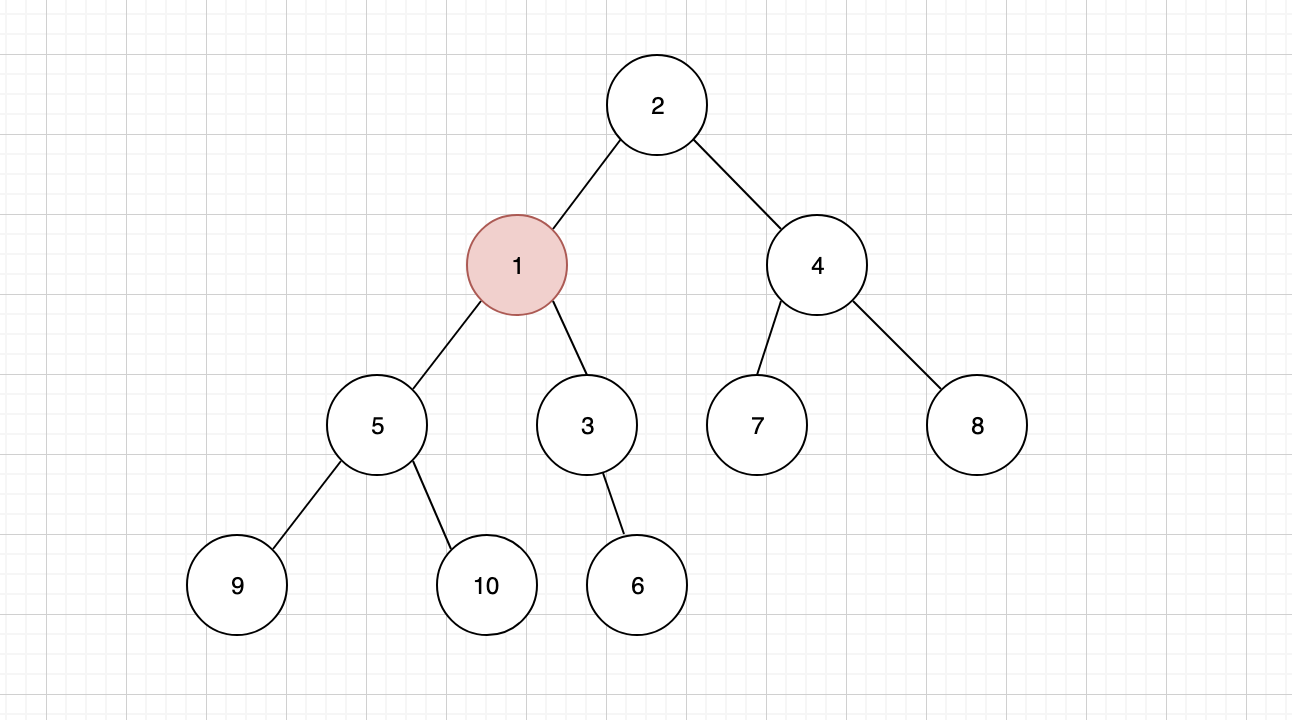
发现新的父节点 2 仍然比 1 大,还要继续上浮,最终让 1 成为新的堆顶
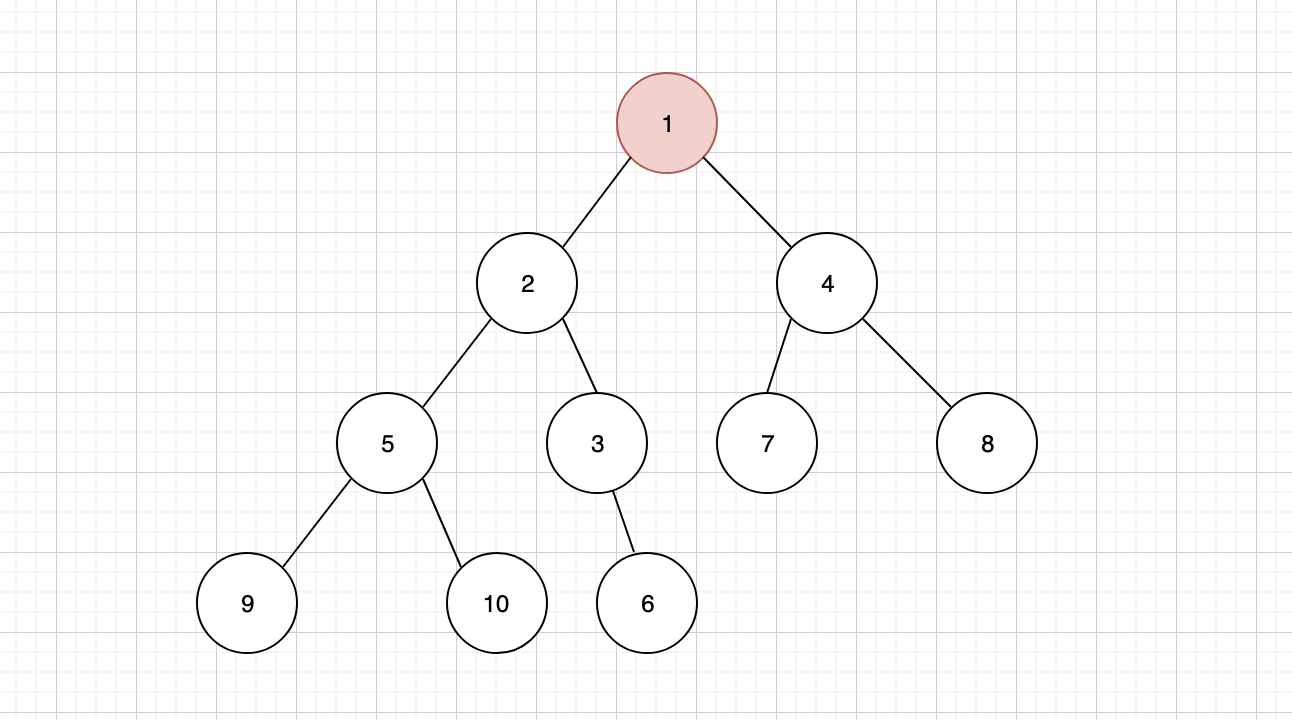
3.2 删除节点
在二叉堆中,我们通常只会删除处于堆顶的元素。
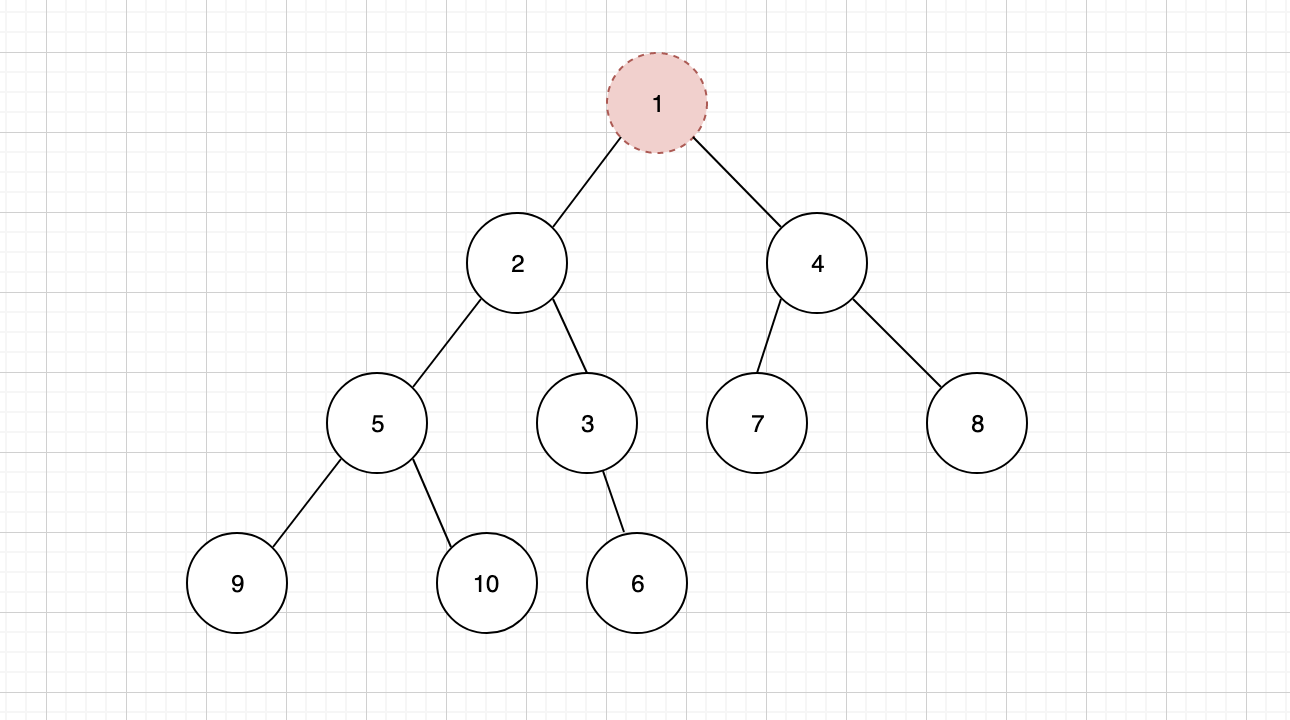
但是删除之后,我们会发现,二叉堆的结构就出现了混乱,为了维持稳定,并且保证二叉堆的特性,还需要在删除之后进行一些调整,首先需要将树结构中的最后一个节点,补充到堆顶位置
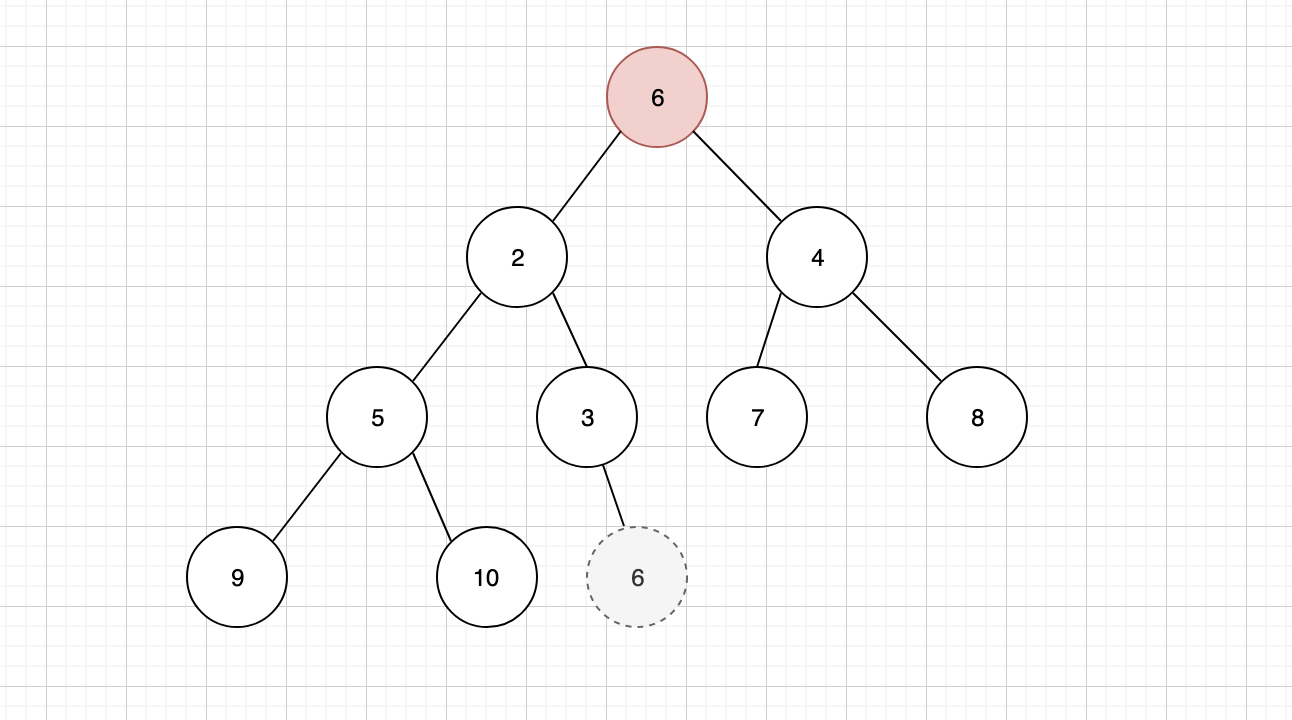
补充之后发现,当前的树结构不符合最小堆的特性,因此需要将新的堆顶元素,与子元素进行比较,找到最小的子元素与其交换位置,这个行为我们称之为「下沉」
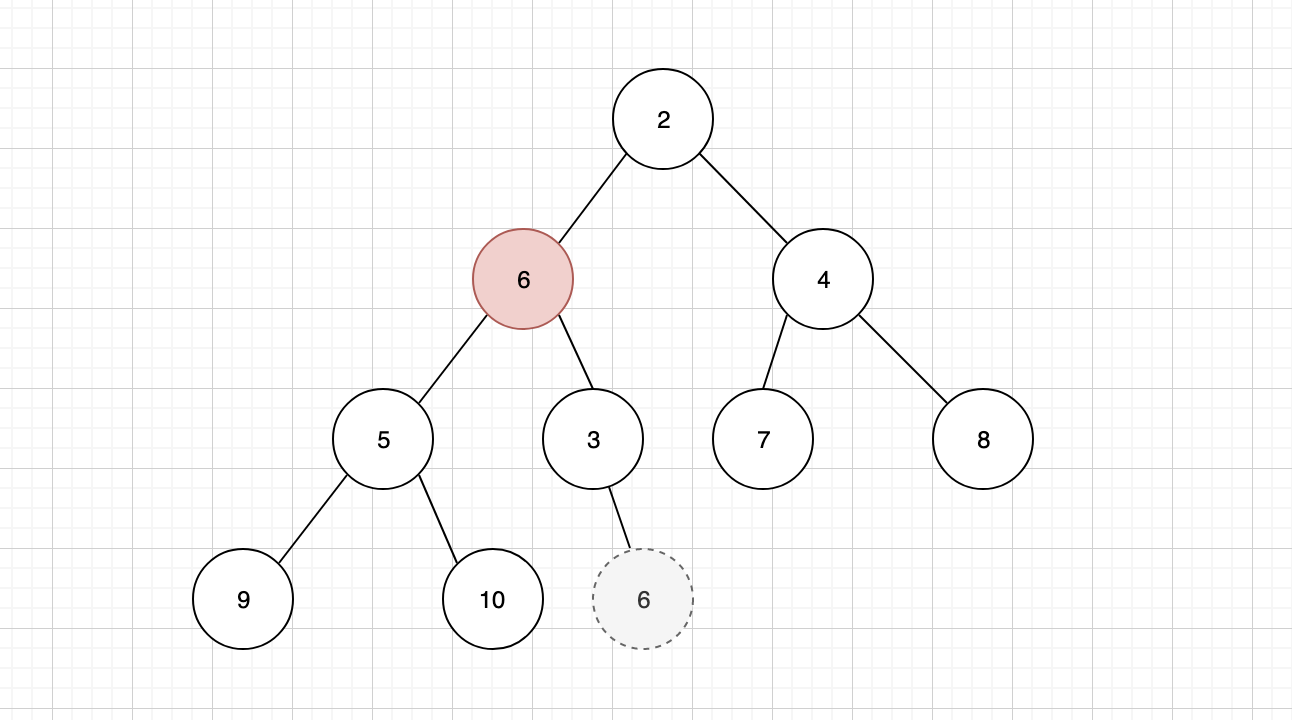
继续与新的子元素进行比较,如果仍然比最小的子元素大,则需要继续下沉,直到完全符合最小堆的规则为止
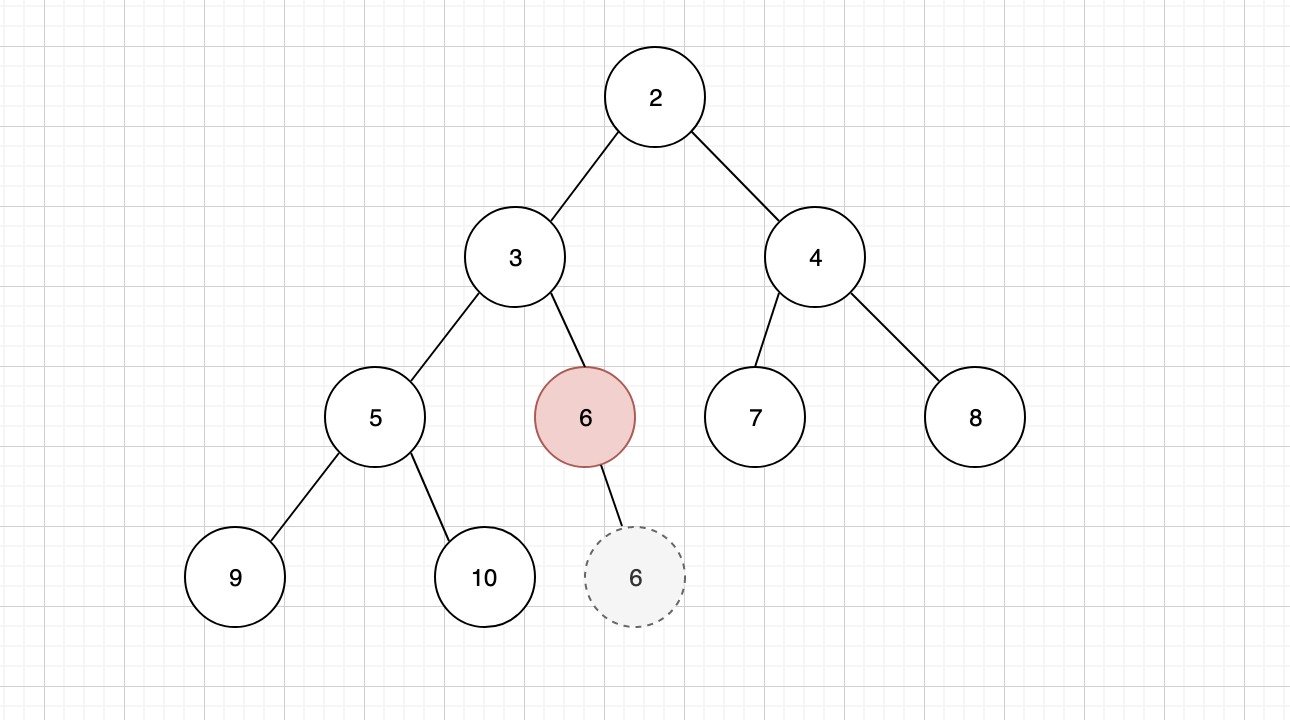
3.3 构建二叉堆
构建二叉堆,本质是一个排序的过程。将不符合规则的二叉树,通过所有非叶子节点依次的下沉操作,调整成为二叉堆。图例与删除节点之后的调整过程几乎一样,因此这里就不再一一展示过程。
代码实现
我们通常基于数组来实现二叉堆。无论是最大堆,还是最小堆它其实都有自己的顺序。并且因为每个节点都最多只有两个子元素,因此我们可以非常方便的使用数组的下标,来在数组中找到对应的子元素。
按照栈数据结构的实现思路,更应该使用类数组的字面量对象来实现,这里的代码因为不涉及到数组操作「所有的逻辑都是自己实现,并未借助数组的其他方法,这里的核心是借助数组的下标」,使用数组更便于大家理解。打印结果也更直观,因此就直接用了数组
例如,如果父节点元素在数组中的下标为 k,那么子元素中,左节点的下标就是 2k + 1,右元素的下标就是 2k + 2。有了这个公式,我们在构建二叉堆时调整位置就很简单了。
3.4 节点公式推导过程
以上面的例子为例,一共有九个节点,我们以 p 代表父节点,l 代表left 左节点,r 代表 right 右节点,那么数组中下标从 0 开始,对应的关系如下
p = 0, l = 1, r = 2
p = 1, l = 3, r = 4
p = 2, l = 5, r = 6
p = 3, l = 7, r = 8
// 当前案例一共只有9个节点,如果节点更多的话,我们还可以继续总结
p = 4, l = 9, r = 10
p = 5, l = 11, r = 12
因此我们很容易发现父节点与左右子节点下标序列的关系 l = 2p + 1, r = 2p +2。因此,当我们知道父节点的下标,就能够找到左右子节点的下标。
反过来会有一点麻烦,如果我们只是知道一个子节点下标,那么如何得到父节点下标呢?把上面的公式调整一下可以得到。
p = (l - 1) / 2
p = (r - 2) / 2
从上面的规律我们可以看出,左节点下标始终是单数,右节点下标始终是双数,为了确保相同的公式又不影响结果,我们可以稍作调整,让他们的公式保持一致。
// 必定等于整数
p = (l - 1) / 2 = Math.floor((l - 1) / 2)
p = (r - 2) / 2 = Math.floor((r - 1) / 2)
于是公式可以统一为
p = Math.floor((i - 1) / 2)
我们先来看看完整的代码实现
class BinaryHeap {
constructor(compare, array) {
this.compare = compare
if (array) {
this.heap = array
this.size = this.heap.length
this.buildHeap()
} else {
this.heap = []
this.size = 0
}
}
// 判断是否为空
isEmpty() {
return this.size == 0
}
// 通过子节点下标,获取节点的父亲节点
parentIndex(i) {
return Math.floor((i - 1) / 2)
}
parent(i) {
return this.heap[this.parentIndex(i)]
}
leftIndex(i) {
return 2 * i + 1
}
// 通过父节点下标,获取父节点的左边子节点
left(i) {
return this.heap[this.leftIndex(i)]
}
rightIndex(i) {
return 2 * i + 2
}
// 通过父节点下标,获取父节点的右边子节点
right(i) {
return this.heap[this.rightIndex(i)]
}
// 节点交换
swap(i, j) {
const temp = this.heap[i]
this.heap[i] = this.heap[j]
this.heap[j] = temp
}
// 插入节点
push(node) {
if (this.size == 0) {
this.size ++
this.heap[0] = node
return
}
this.size ++
let i = this.size - 1
this.heap[i] = node
while(i != 0 && this.compare(this.heap[i], this.parent(i))) {
this.swap(i, this.parentIndex(i))
i = this.parentIndex(i)
}
}
// 无论是删除元素,或者说构建二叉堆,都需要重新排序,封装统一的方法来支持排序过程,
// 叶子节点不会调用此方法
// 向下调整
heapify(i) {
// 找到最小的元素
const l = this.leftIndex(i)
const r = this.rightIndex(i)
const pv = this.heap[i],
lv = this.heap[l],
rv = this.heap[r]
let small = i
if (l < this.size && this.compare(lv, pv)) {
small = l
}
if (r < this.size && this.compare(rv, this.heap[small])) {
small = r
}
if (small != i) {
this.swap(i, small)
this.heapify(small)
}
}
// 删除堆顶元素
pop() {
if (this.size <= 0) {
return null
}
if (this.size == 1) {
let node = this.heap[this.size - 1]
this.size --
this.heap.length = this.size
return node
}
const root = this.heap[0]
this.heap[0] = this.heap[this.size - 1]
this.size --
this.heap.length = this.size
this.heapify(0)
return root
}
// 获取堆顶元素
top() {
return this.heap[0]
}
// 构建堆,从最后一个非叶子节点开始遍历构建
buildHeap() {
for (let i = this.parentIndex(this.size - 1); i >= 0; i--) {
this.heapify(i)
}
}
}
function compare(a, b) {
return a < b;
}
var heap = new BinaryHeap(compare);
heap.push(1);
heap.push(2);
heap.push(3);
heap.push(4);
heap.push(5);
console.log(heap.heap) // [1, 2, 3, 4, 5]
heap.pop()
console.log(heap.heap) // [2, 4, 3, 5]
var array = [150, 80, 40, 30, 10, 70, 110, 100, 20, 90, 60, 50, 120, 140, 130];
var h = new BinaryHeap(compare, array);
console.log(h.heap) // [10, 20, 40, 30, 60, 50, 110, 100, 150, 90, 80, 70, 120, 140, 130]
具体代码完全按照上面图例中的逻辑来实现,相信理解起来并不困难,不过这里需要注意的是,我们往构造函数中,传入了两个参数,compare 与 array。
许多同学可能会对 compare 不是很理解。compare 是传入的一个比较函数,该比较函数必须接收两个节点作为参数,并且返回这个两个节点的比较结果。这样我们可以通过自定义该比较函数的内容,来确定最终结果是最大堆还是最小堆。
function compare(a, b) {
// 小顶堆
return a < b;
}
function compare(a, b) {
// 大顶堆
return a > b;
}
在我们的代码实现中,比较函数对于内部逻辑的排序非常有帮助,例如插入节点时,节点首先会插入到最末尾的节点,然后通过比较其父节点的大小,进行位置交换的调整。因此只要比较结果符合 compare 的预期,我们就可以将当前节点与父节点进行位置交换
push(node) {
if (this.size == 0) {
this.size ++
this.heap[0] = node
return
}
this.size ++
let i = this.size - 1
this.heap[i] = node
while(i != 0 && this.compare(this.heap[i], this.parent(i))) {
this.swap(i, this.parentIndex(i))
i = this.parentIndex(i)
}
}
除此之外,在实践中,参与比较的可能并非节点本身,而是节点的某个字段。
const array = [
{name: 'Jake', id: 29},
{name: 'Toms', id: 22},
{name: 'Jone', id: 40},
...
]
这个时候,我们要针对这样的数组构建一个二叉堆,比较函数就会按照需求比较 id,而非节点本身
function compare(a, b) {
// 小顶堆
return a.id < b.id;
}
function compare(a, b) {
// 大顶堆
return a.id > b.id;
}
在数组的自身已经支持的 sort 方法也采用了类似的解决方案来决定排序的结果
var array = [150, 80, 40, 30, 10, 70, 110, 100, 20, 90, 60, 50, 120, 140, 130];
// 由小到大排序
var _a = array.sort((a, b) => a - b)
console.log(_a) // [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120, 130, 140, 150]
// 由大到小排序
var _b = array.sort((a, b) => b - a)
console.log(_b) // [150, 140, 130, 120, 110, 100, 90, 80, 70, 60, 50, 40, 30, 20, 10]
节点元素不能直接参与比较,使用某个字段进行比较
const persons = [
{ name: 'Jake', id: 29 },
{ name: 'Toms', id: 22 },
{ name: 'Jone', id: 40 },
{ name: 'Alex', id: 3 },
]
const p1 = persons.sort((a, b) => a.id - b.id)
console.log(p1) // 结果为按照 id,从小打大排序
// 因为引用类型的关系,下面的代码请分开执行,否则眼睛看到的打印结果将会是最后一次的排序结果
const p2 = persons.sort((a, b) => b.id - a.id)
console.log(p2) // 结果为按照 id,从大到小排序
除了 sort 方法之外,map, filter, reduce, some, every 等方法,都采用了类似的思维,传入一个条件,根据条件的执行结果,返回新的内容。这样的封装思维,我们在高阶函数中会进一步详细解读。
部分逻辑使用了递归实现,如果对这部分不是很理解,可以专门查阅资料学习递归的使用之后再来学习。
3.5思考题
理解了 compare 的使用之后,你能否尝试自己封装一个数组的 map 方法?
二叉树作图工具地址:freedgo
4 数据结构:队列
队列是一种先进先出的数据结构。
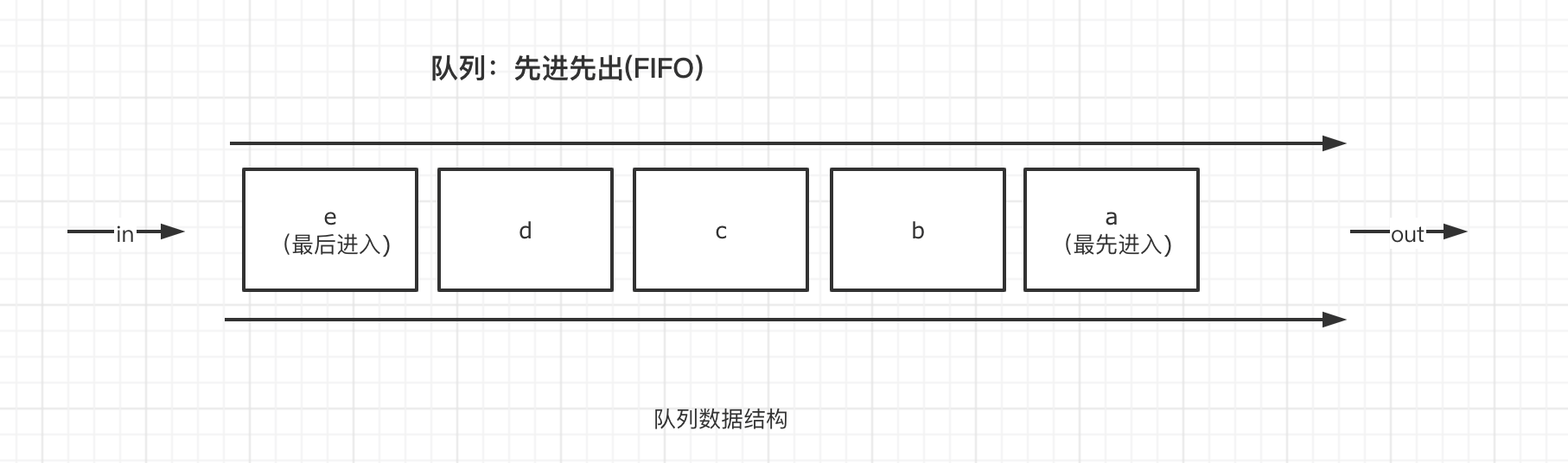
image.png
如果要将队列运用到实践中,很容易就能够想到会有如下操作
- 从队列最后入队
- 从队列头部出队
- 从队列任意位置离队「有其他事情」
- 从队列任意位置插队「特殊权利」
- 清空队列
如果要用代码来实现一个队列对象,应该怎么办?
在思考这个问题之前,我们需要讨论一下使用什么样的基础数据结构来保存队列的数据。如果你对数组很熟悉,那么就能够很自然的想到使用数组来存储队列数据,但是我们仔细分析一下会发现,上面这些方法,数组全都已经实现过了。因此我们常常在实践中可以直接使用数组来表达一个队列。不过这样的话,就失去了学习的意义。因此我们基于更基础的对象字面量来表达队列,使用从 0 开始的数字作为 key 值,构建一个类数组对象,如下
this.queue = {
0: 'A',
1: 'B',
2: 'C',
3: 'D'
}
序列表示队列位置,序列对应的值,表示队列成员。
那么,队列对象的基本代码结构就应该如下
class Queue {
constructor() {
this.length = 0
this.queue = {}
}
// 从队列尾部进入
push(node) {}
// 从队列头部出队
shift() {}
// 特殊情况的插队处理,在 i 前面插队
inset(i, node) {}
// 特殊情况的离队处理,队列中的任意位置离队
out(i) {}
clear() {}
}
接下来就是实现具体的功能函数。
push,从队列尾部进入队列,该方法实现比较简单,当有一个成员入队,那么队列的长度自然要加 1,并且新增序列,用于对应新加入的队列成员
push(node) {
this.queue[this.length] = node
this.length++
return this.queue
}
shift,从队列头部出队。假设我们已经有这样一个队列,如下
this.queue = {
0: 'A',
1: 'B',
2: 'C',
3: 'D',
4: 'F'
}
从队列首部删除一个,那么队列就变成
this.queue = {
0: 'B',
1: 'C',
2: 'D',
3: 'F'
}
很容易能发现,序列始终保持从 0 开始,这也是队列的基本规则。之前的首位出去之后,第二个元素成为了新的队首。最终序列 4 消失不见,而队列成员对应的序列则依次向前进了一位。明白这个变化之后,代码实现就变得容易了
// 从队列头部出队
shift() {
const rq = this.queue[0]
for (let i = 0; i < this.length - 1; i++) {
this.queue[i] = this.queue[i + 1]
}
delete this.queue[this.length - 1]
this.length--;
return rq
}
insert 方法 与 out 方法同理,删除或者新增一个队列成员之后,我们针对性的调整序列与成员之间的对应关系即可。完整代码如下:
class Queue {
constructor() {
this.length = 0
this.queue = {}
}
// 从队列尾部进入
push(node) {
this.queue[this.length] = node
this.length++
return this.queue
}
// 从队列头部出队
shift() {
const rq = this.queue[0]
for (let i = 0; i < this.length - 1; i++) {
this.queue[i] = this.queue[i + 1]
}
delete this.queue[this.length - 1]
this.length--;
return rq
}
// 特殊情况的插队处理,在 i 前面插队
inset(i, node) {
this.length++
for (let k = this.length - 1; k > i; k--) {
this.queue[k] = this.queue[k - 1]
}
this.queue[i] = node
return this.queue
}
// 特殊情况的离队处理,队列中的任意位置离队
out(i) {
const rq = this.queue[i]
for (let k = i; k < this.length - 1; k++) {
this.queue[k] = this.queue[k + 1]
}
delete this.queue[this.length - 1]
this.length--
return rq
}
clear() {
this.length = 0
this.queue = {}
}
}
运用到实践中时,可能还会新增更多额外的处理方式,例如:
- 判断某个成员,是否正在队列中
- 由于紧急情况,成员需要在队列中处于挂起状态去处理别的事情,激活之后不需要重新排队,而是直接处于队列的原有位置「如果队列往前移动了,也跟着移动,始终不出队」
- 按照优先级排队,始终让优先级最高的队列成员,处于队首。因此这种情况之下,任何队列成员的变动都需要重新排序,确保队首的成员优先级最高,我们上一章节学习过的二叉堆,就可以实现这种优先级队列
4.1 思考题
10 个员工处理 1000+ 个来访客户的业务。这 1000+ 个客户会在一天内的不同时间陆续来访。那么如何利用队列的思维,来保证来访者的公平性「先到先处理」,以及保证来访任务的相对合理分配?
除此之外,你还能在生活中,发现哪些队列的运用场景?
5 数据结构:链表
链表是一种递归的数据结构,它由多个节点组成,节点之间使用引用相互关联,组成一根链条。
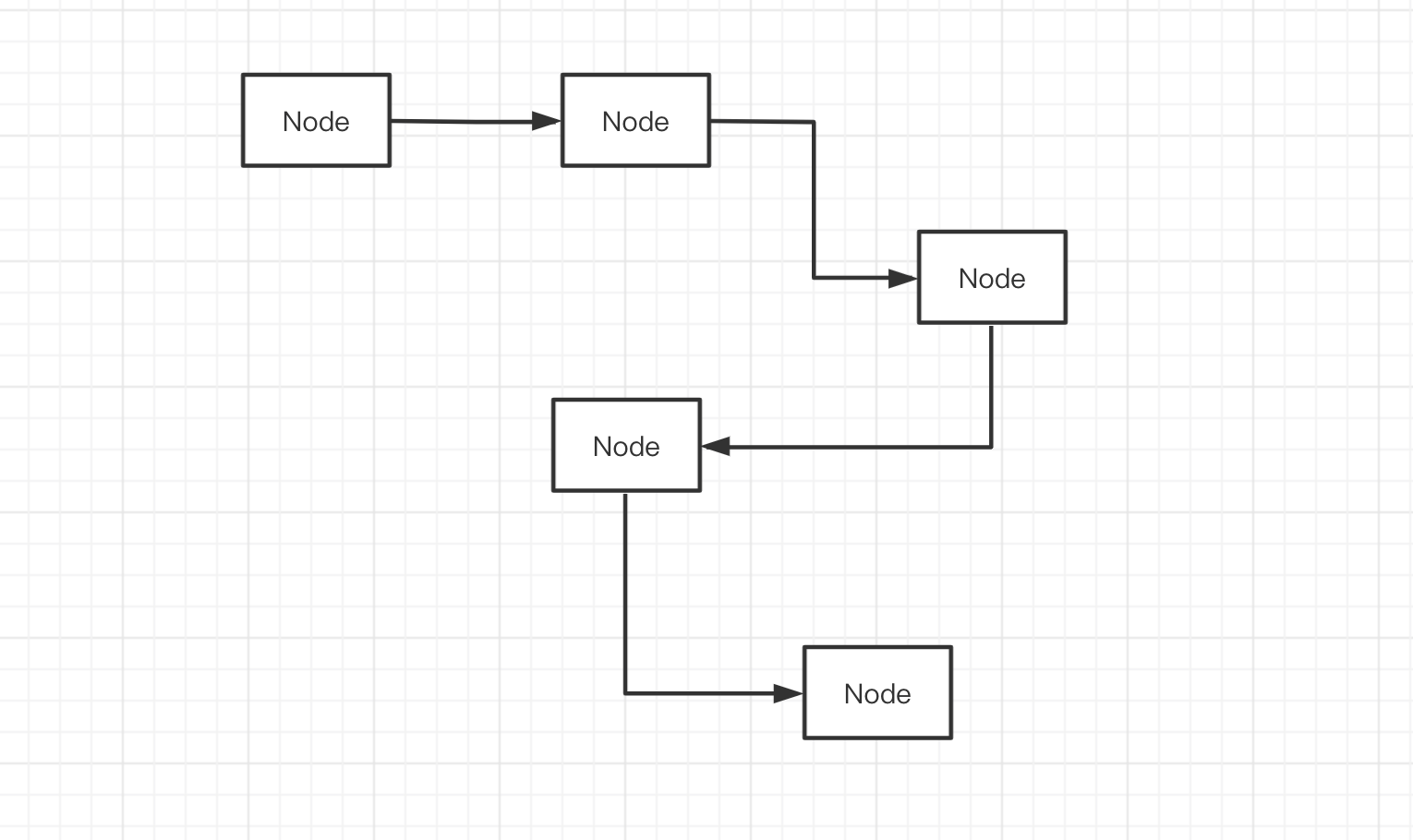
image.png
从上图中,我们可以总结出链表的几个特征
- 在内存中,链表是松散不连续的结构,通过引用确定节点之间的联系,不像数组那样,是排列在一起的连续内存地址
- 链表没有序列,如果引用是单向的,只能通过上一个节点,找到下一个节点
- 节点之间的引用可以是单向的「单向链表」,也可以是双向的「双向链表」,还可以首尾连接「循环链表」
从知识点的角度来说,链表与数组几乎是一对孪生兄弟,他们都能解决同样的问题。
链表的节点通常是这样一个类似的对象
// ts 语法,用于描述 Node 对象的具体结构
type Node = {
// 指向其他节点的引用
next: Node,
prev: Node,
// 其他表示这个节点具体内容的属性
tag: string,
type: number
...
}
next 与 prev 属性,表示节点中指向下一个节点或者上一个节点的引用,该引用的属性名在不同的引用场景中可能命名不同。其他的属性,则表示该节点的具体内容。我们可以通过 next 与 prev 找到其他节点。
在学习过程中我们能够遇到非常多这样的案例,例如 HTML div 元素对象中有这样两条属性
// 伪代码
div = {
nextSibling: nextDiv
previousSibling: prevDiv
...
}
又例如在原型链中,每一个实例对象,都有一个 __proto__ 属性,用以指向该实例的原型对象。该原型对象,自身也会有一个 __proto__ 属性,指向自己的原型对象。

image.png
原型链是一个由 __proto__ 进行关联的单向链表。
又例如在 React 源码实现中,会对多任务进行切片,每一个切片就是一个 Fiber 节点。而这个节点的数据结构大概如下,暂时可只关注前两个属性,我们会发现链表的体现
// ts 语法,用于表示一个节点的数据结构
type Fiber = {
// 单向链表引用:指向自己的第一个子节点
child: Fiber | null,
// 单向链表引用:快速查找下一个 side effect
nextEffect: Fiber | null,
// Fiber 节点的其他属性,可忽略
tag: WorkTag,
key: null | string,
elementType: any,
type: any,
stateNode: any,
sibling: Fiber | null,
return: Fiber | null,
index: number,
ref: null | (((handle: mixed) => void) & {_stringRef: ?string}) | RefObject,
pendingProps: any,
memoizedProps: any,
updateQueue: UpdateQueue<any> | null,
memoizedState: any,
firstContextDependency: ContextDependency<mixed> | null,
mode: TypeOfMode,
effectTag: SideEffectTag,
firstEffect: Fiber | null,
lastEffect: Fiber | null,
expirationTime: ExpirationTime,
childExpirationTime: ExpirationTime,
alternate: Fiber | null,
actualDuration?: number,
actualStartTime?: number,
selfBaseDuration?: number,
treeBaseDuration?: number,
_debugID?: number,
_debugSource?: Source | null,
_debugOwner?: Fiber | null,
_debugIsCurrentlyTiming?: boolean,
};
因为链表的松散性,如果我们要在实践中使用链表,只需要约定好每个节点的数据格式,在创建节点时,通过引用指向上一个节点或者下一个节点即可。因此我们往往会依据上一个节点来创建下一个节点,这样很容易建立联系,而不是凭空产生。
例如我们创建一个数组对象,是根据 Array 对象来创建
// new 的实现中,完成了 __proto__ 的指向
var arr = new Array()
这样 实例 arr 就依据 Array 对象,加入了原型链中。
所以,我们可以看出,链表常常用于解决不关注序列的的线性场景。
从知识点的角度分析,数组与链表可以算是一对孪生兄弟。都是作为线性数据结构,几乎能够解决同样的问题。我们完全可以定义一个 LinkedList,实现与 Array 一模一样的功能。但是他们在内存空间中的位置特性,决定了他们适应的场景不一样
链表,在内存空间是松散的,不连续的。因此,如果我们要关注链表的序列的话,就很麻烦。我们需要找到头部节点,根据引用找到下一个节点,然后再依次找下去。也就是说,如果想要找到链表中的第 9 个节点,那么我们必须要依次找出前面 8 个节点,才能通过第八个节点的引用,知道第九个节点是谁。而数组就没那么麻烦,可以通过序列直接找到第九个元素。
数组,在内存空间是紧密的,连续的。那么也就意味着,如果我要在长度为 100 的数组中的第二个位置,新增一个成员,后面的 99 个数组成员,在内存空间中都得往后挪动位置,这样才能空出新的空间让新成员加入。而链表在新成员加入的时候就没那么麻烦,因为空间的不连续性,新节点不需要任何成员让位置。
在性能的角度上考虑,访问某个成员,数组远远优于链表,而如果新增/删除元素,链表远远优于数组。因此基于这个特性,面对实际场景,我们要选择最适合的解决方案。
单向链表的代码实现
// 单向链表
class LinkedList {
constructor() {
this.length = 0
this.head = null // 链表首部节点
}
// 约定此时的节点格式
createNode(number) {
return {
num: number,
next: null
}
}
push(number) {
const node = this.createNode(number)
if (!this.head) {
this.head = node
this.length++
return node
}
let current = this.head
// 此处的节点处理是关键,从头部开始遍历,只要还能找到下一个,说明就还不是最后一个,直到最后找不到了,就表示 current 指向了最后的节点
while (current.next) {
current = current.next
}
current.next = node
this.length++
return node
}
// 根据索引位置,插入新节点:默认此处传入的 i 值 >= 0,小于 length
insert(i, number) {
const node = this.createNode(number)
let curIndex = 0, prevNode = null, current = this.head;
if (i == 0) {
node.next = current
this.head = node
return node
}
// 找到 i 对应的节点
while (curIndex++ < i) {
prevNode = current
current = current.next
}
// 上一个节点指向新增节点,新增节点指向下一个节点
node.next = current
prevNode.next = node
this.length++
return node
}
// 找到节点所在的位置
indexOf(number) {
let index = -1, curIndex = -1, current = this.head
// 直到找到最后一个节点
while (current) {
index++
if (current.num == number) {
curIndex = index
break
}
current = current.next
}
return curIndex
}
// 根据索引位置,删除节点,默认 i 值是合理的
remove(i) {
let prevNode = null, current = this.head, curIndex = 0;
if (i == 0) {
const rmNode = current
this.head = current.next
return rmNode
}
while(curIndex++ < i) {
prevNode = current
current = current.next
}
// 被删除的节点
const rmNode = current
prevNode.next = current.next
return rmNode
}
}
上面代码实现,引入了索引位置的概念来实现链表的部分功能。我们发现,一旦涉及到位置信息,都需要进行遍历处理,这也是链表在索引位置上的弊端所在。
我们还可以根据实际需求再新增新的方法。双向链表的实现也只需要额外多处理一个 prev 引用即可。
5.1 思考题:
需要排序的应用场景「例如我之前章节中实现的二叉堆」,适合用链表来实现吗?为什么?
6 引用数据类型
引用数据类型在实践中是一个雷区。由于引用类型引发的惨案,也频频发生。进一步掌握引用类型,是作为一个合格前端开发必不可少的学习过程。
引用类型,是可变的。当我们操作引用类型时,如果不小心,就可能会出现我们意想不到的结果。
6.1 纯函数
纯函数,是我们在学习函数式编程时,会接触到的概念。在维基百科中,这样介绍纯函数:
若一个函数符合以下要求,它就可以被认为是一个纯函数
- 此函数在相同的输入值时,总会产生相同的输出。函数的输出与输入值以外的其他隐藏信息或者状态无关,也和 I/O 设备产生的外部输出无关。
- 该函数不能有语义上可观察的函数副作用,例如“触发事件”
也就是说,纯函数的输出值,只和输入值有关,与其他因素都没有关系,也不能被外界干扰而影响输出或者影响外界的其他值。
那么我们看看下面这个例子中定义的函数,是纯函数吗?
var person = {
name: 'Tim',
age: 20
}
function setting(p, name, age) {
p.name = name;
p.age = age;
return p;
}
var a = setting(person, 'Jake', 10);
console.log(a);
console.log(person);
console.log(a === person);
思考一分钟。
输入结果很奇怪,a 与 person 居然完全相等。他们都对应的是同一个对象。
分析一下这个例子。这里关键就在 setting 方法的第一个参数。当我们使用该方法时,将引用类型 person 作为一个参数传入了函数。然后就在函数中直接修改了传入的 person 属性。并将修改之后的结果返回。在这个过程中,person 的引用始终保持不变。
因此当我们使用变量 a 接收 setting 的执行结果时,其实也只是做了一个引用类型的赋值操作。于是变量 a 与 person 指向了同样的内存空间。
这种情况下,setting 函数就不能称之为纯函数了,因为它修改了外部的数据。这就是副作用。甚至我们还可以在函数执行完毕之后,修改 person 的值,这样 a 的值还会被改变,于是函数执行结果就变得不再可靠。
正因为这样,我们在创建纯函数时,就必须要万分警惕引用类型带来的影响。
实践过程中,我们有时候希望改变原有数据,但更多的时候是不希望改变原有数据「这种情况下基础数据类型的不可变特性,反而更为可靠」。例如一个简单的案例
var foo = {
a: 1,
b: 2
};
var bar = Object.assign(foo, { c: 100 });
console.log(foo, bar);
我们希望得到一个新的值,结合 foo 所有属性与 {c: 100} 。于是使用 Object.assign 来实现。如果你对该方法了解不深,就会带来意想不到的结果。因为在这个过程中,原数组 foo 被改变了。
Object.assign 并不是一个纯函数。如果要达到得到一个新的值的目的,需要使用一些技巧来避免它本身的副作用。
var bar = Object.assign({}, foo, { c: 100 })
这样会修改原数组的类似方法还不少,例如操作数组的 api:splice
const arr = [1, 2, 3, 4, 5, 6, 7, 9];
arr.splice(7); // 对原数组arr的值造成影响
console.log(arr);
所以学习数组方法时,我们也要区分出来哪些是会改变原数组的,哪些不会改变。
3.2 拷贝/比较
引用数据类型的拷贝与比较略显复杂。我们知道,如果只是变量之间的拷贝与比较,参与的都是内存地址,而并非真正的值本身。因此,结果往往不尽人意。也因为这样,才有了浅拷贝,深拷贝,浅比较、深比较的概念。
6.2.1浅拷贝
对于浅的概念没有非常严格的界定。直接赋值变量是一种浅拷贝,仅仅只拷贝引用类型的第一层也算一种浅拷贝。
var a = { m: 1 }
// 通过赋值,实现浅拷贝
var b = a
这种方式在实践中的意义并不大,因为无论通过变量 a 还是变量 b 操作数据,都是修改的同样的对象。
一起来看看这个例子
var foo = {
a: 10,
b: {
m: 20,
n: 30
}
}
var copy = Object.assign({}, foo);
// 属性a的值,是基础数据类型,直接改变不会影响原值foo
copy.a = 20;
// 属性b是引用数据类型,浅拷贝仅仅只是第一层数据创建新的内存,而第二层数据指向同样的内存值,因此改变会影响foo的值。
copy.b.m = 100;
console.log(copy);
console.log(foo);
观察 copy 和 foo 的最终结果,对于 a 的操作互不干扰,而对于 m 的操作,则相互影响。这就是浅拷贝。除了第一层引用不同,更深层次的引用都是相同的。
可以封装一个通用的浅拷贝工具函数,代码如下;
/**
* desc: 判断一个值的具体数据类型
*/
function type(value) {
return Object.prototype.toString.call(value).split(' ')[1].slice(0, -1)
.replace(/^[A-Z]{1}/, (p) => p.toLowerCase());
}
/** 浅拷贝 */
export function clone(target) {
let res = null;
if (type(target) === 'array') {
res = [];
target.forEach(item => {
res.push(item);
})
}
if (type(target) === 'object') {
res = {};
Object.keys(target).forEach(key => {
res[key] = target[key];
})
}
// 如果需要完善后运用于生产环境,则需要在继续分别考虑各种其他数据类型,例如基础数据类型,函数,Map,并分别处理等
return res || target;
}
const x = { a: 1, b: { m: 1, n: 2 } };
const y = clone(x);
console.log(y);
y.b.m = 20;
console.log(x); // y修改b属性之后,x也受到影响
const a1 = [1, 2, { m: 1, n: 2 }];
const a2 = clone(a1);
console.log(a2);
a2[2].m = 100;
console.log(a1); // a2修改第三个值,a1也受到影响
浅比较
浅比较与浅拷贝,在浅的概念上是一样的。
浅比较的应用比较广泛,以 React 为例「Vue 也类似」,每一个 React 组件本质上就是一个引用数据类型,不过通常情况下这个引用数据类型比较复杂。因此当我们期望判断出一个组件是否需要更新时,如果使用深比较来判断变化的话,性能上的消耗会远超我们的预期。
也正因为如此,我们在试图使用 PureComponent 和 shouldComponentUpdate 来优化性能时,如果运用不合理,可能会造成额外的性能损耗
React 中,浅比较的实现方法
// React中,浅比较的实现方法
const hasOwn = Object.prototype.hasOwnProperty
function is(x, y) {
if (x === y) {
return x !== 0 || y !== 0 || 1 / x === 1 / y
} else {
return x !== x && y !== y
}
}
export default function shallowEqual(objA, objB) {
if (is(objA, objB)) return true
if (typeof objA !== 'object' || objA === null ||
typeof objB !== 'object' || objB === null) {
return false
}
const keysA = Object.keys(objA)
const keysB = Object.keys(objB)
if (keysA.length !== keysB.length) return false
for (let i = 0; i < keysA.length; i++) {
if (!hasOwn.call(objB, keysA[i]) ||
!is(objA[keysA[i]], objB[keysA[i]])) {
return false
}
}
return true
}
6.2.2 深拷贝
深拷贝必须要每个引用类型都使用新的内存空间,做到拷贝前后完全不相互影响。
/**
* auth: yangbo
* desc: 判断一个值的具体数据类型
*/
function type(value) {
return Object.prototype.toString
.call(value)
.split(" ")[1]
.slice(0, -1)
.replace(/^[A-Z]{1}/, p => p.toLowerCase());
}
/** 深拷贝 */
export function deepClone(target) {
let res = null;
if (type(target) === "array") {
res = [];
target.forEach(item => {
res.push(deepClone(item));
});
}
if (type(target) === "object") {
res = {};
Object.keys(target).forEach(key => {
res[key] = deepClone(target[key]);
});
}
// 如果需要完善后运用于生产环境,则需要在继续分别考虑各种其他数据类型,例如基础数据类型,函数,Map,并分别处理等
return res || target;
}
const x = { a: 1, b: { m: 1, n: 2 } };
const y = deepClone(x);
console.log(y);
y.b.m = 20;
console.log(x); // y修改b属性之后,x不受影响
const a1 = [1, 2, { m: 1, n: 2 }];
const a2 = deepClone(a1);
console.log(a2);
a2[2].m = 100;
console.log(a1); // a2修改第三个值,a1不受影响
深比较同理,因为几乎不在实践中使用,这里就不再做额外的介绍。
6.3 不可变数据集
** 不可变数据是函数式编程的重要概念。从上面关于纯函数的学习中我们得知,对于函数式编程而言,引用数据类型的可变性,简直是“万恶之源”。
我们在函数式编程的实践中,往往期望引用数据类型也具备基础数据类型不可变的特性,这样能使开发变得更加简单,状态可回溯,测试也更加友好。因此在开发中探索不可变数据集,是必不可少的行为。
最常规的办法就是使用完全深拷贝。很显然,由于性能的问题,在实践中使用深拷贝来达到不可变数据集的目的并不靠谱。我们常常会引入 immutable.js,immer.js 来达到目的。
不可变数据集常常用于大型项目,虽然底层实现思路优于深拷贝,但也会造成一定的性能损耗与内存。因此做技术选型时一定要综合考虑优劣。慎重采纳。
不可变数据集会在新书《React 核心进阶》中深入介绍,此处仅仅只是提供一个简单的概念,大家有进一步学习的可以查阅相关资料进行学习。
附录:基础数据类型为何是不可变数据
这跟垃圾回收机制的工作逻辑有关。
首先我们需要明确一点,JavaScript 中的任何内存,不能凭空回收,而只能由垃圾回收器回收。
其次需要明确第二点,回收器会周期性的遍历内存空间,找到内存垃圾然后进行回收利用。也就意味着,垃圾产生的那一刻,并不会立刻被回收,而是要等到垃圾回收器遍历到此处时,才会被回收。
这个过程就如同扫地机器人。扫地机器人在屋内转圈圈,当你向地上扔一个垃圾时,如果没有扔在扫地机器人的面前,它就不会再那一瞬间将垃圾吸收走,而是要等到它走到垃圾处时,垃圾才会被收走。
此时我们来分析一个简单的值改变的代码
var a = 10
a = 20
我们首先声明变量 a = 10 ,并且将变量修改为 20。当我给变量 a 赋值为 10 的时候,此时内存空间中,会分配一个空间,专门存放 10 这个数字。
当我们将一个新的数字 20 赋值给 a 时,此时 10 这个数字成为了垃圾,这里许多人就会误解,那我能不能就在 10 这个内存空间的位置,直接填充 20 ?不能!因为垃圾回收器不会闪现过来处理这个逻辑。
因此,10 所占的内存空间不能立即释放,需要等待垃圾回收器,而此时只能给 20 分配一个新的内存空间,10 因为失去了引用,成为了内存垃圾,等待被回收。
所以,我们可以推断出,基础数据类型,在内存中是不可以被改变的。